
机器学习基本概念
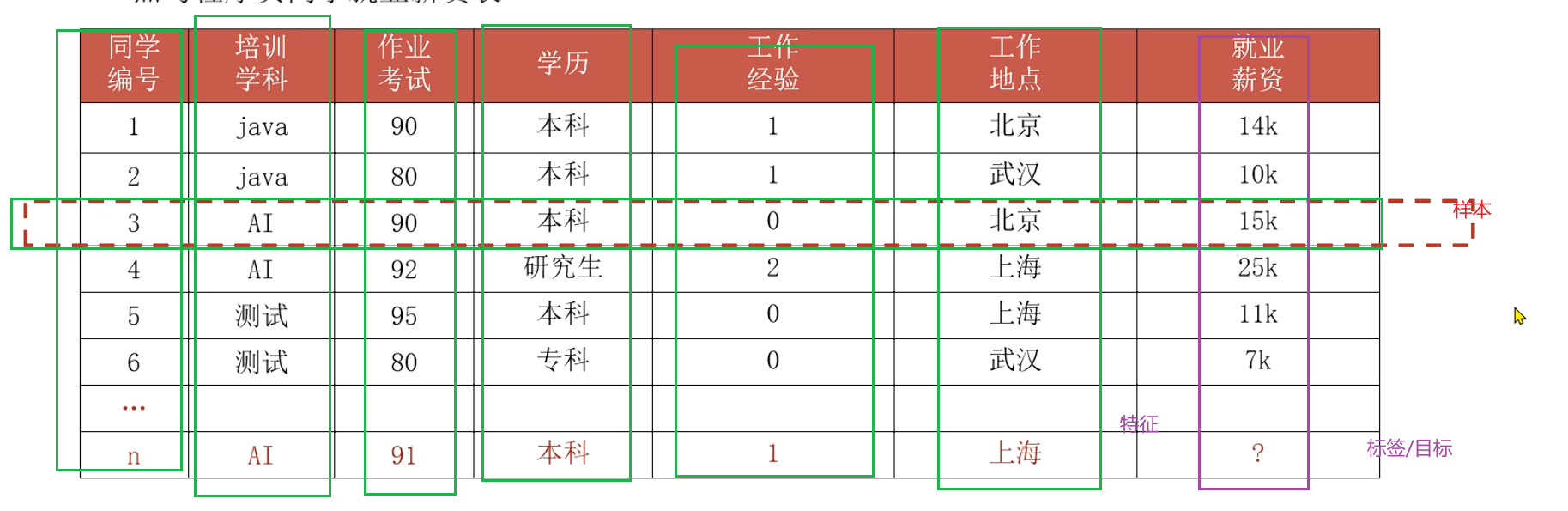
样本、特征、标签
样本: 一行数据就是一个样本;多个样本组成一个数据集;有时一条样本被叫一条记录
特征: 一列数据有一个特征,有时也被称为属性
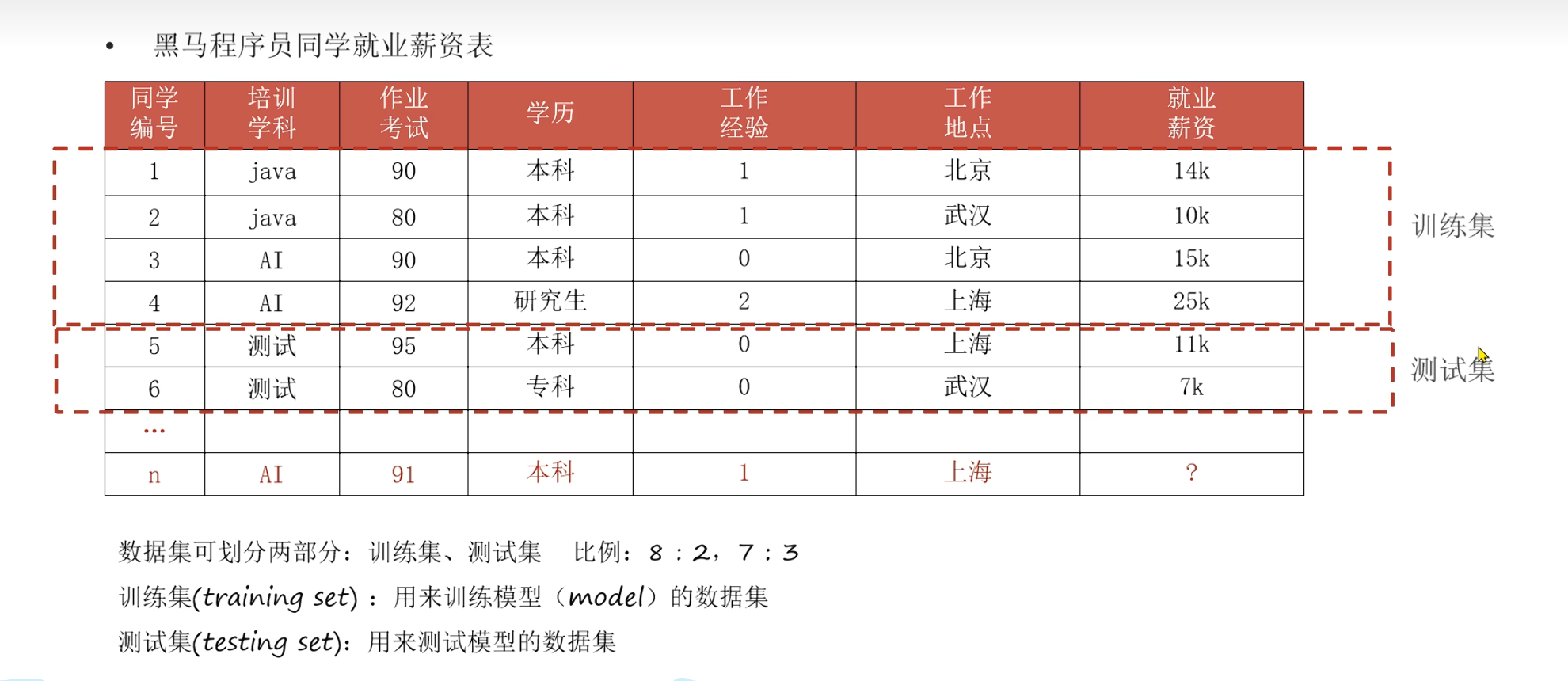
训练集和测试集
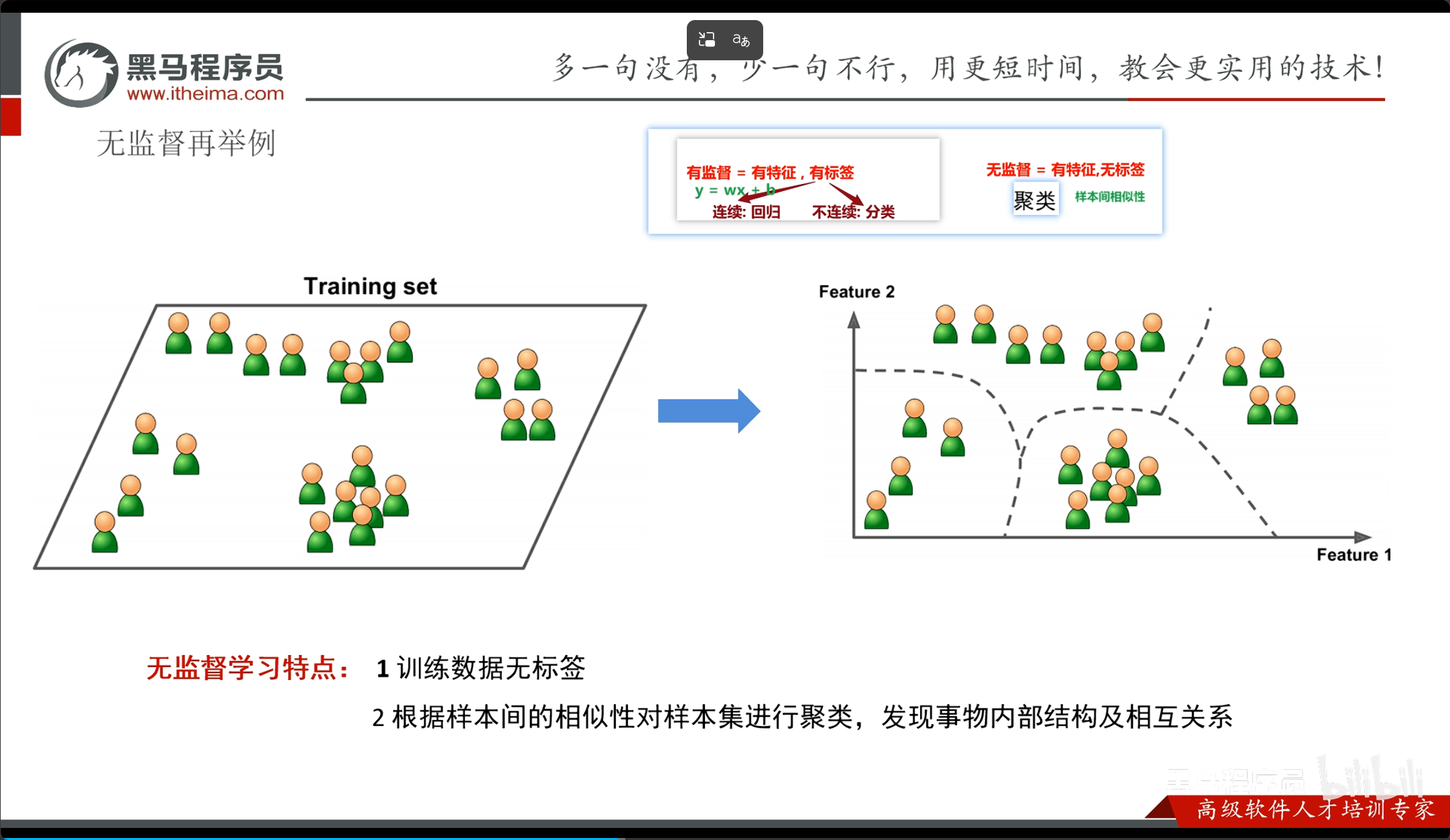
机器学习算法分类

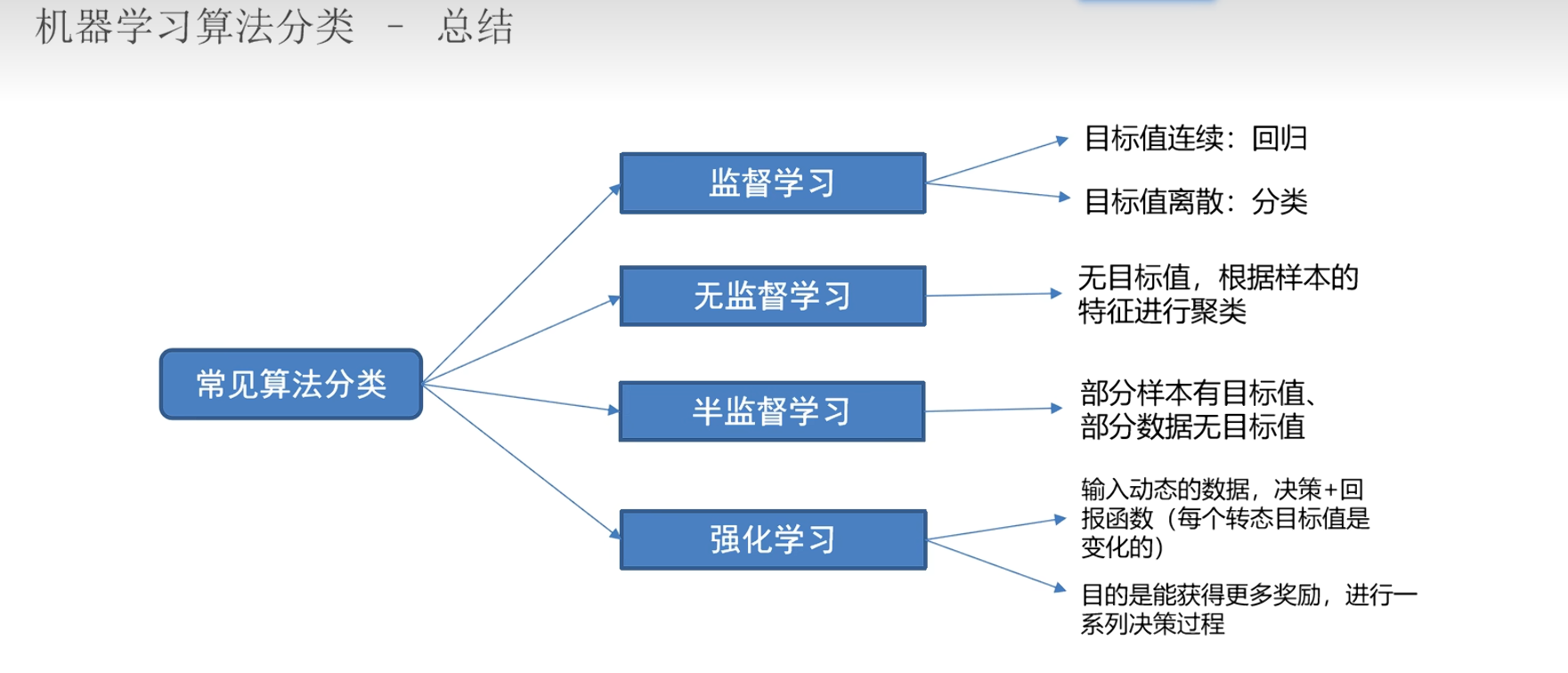
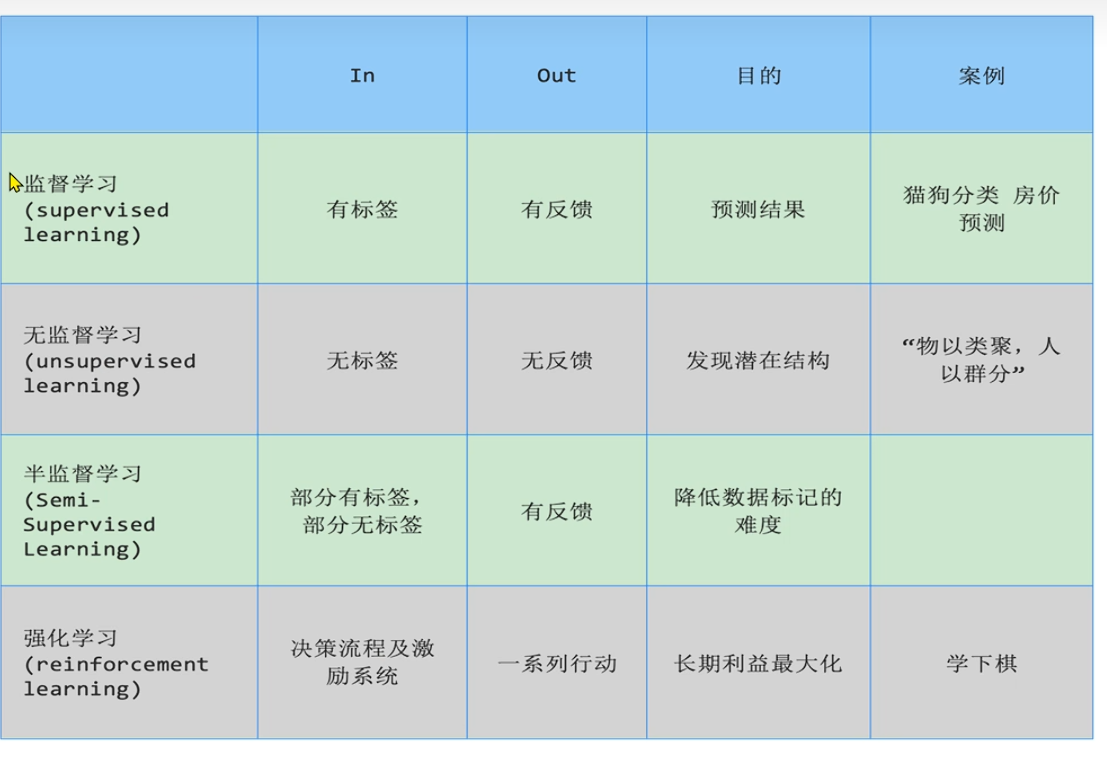
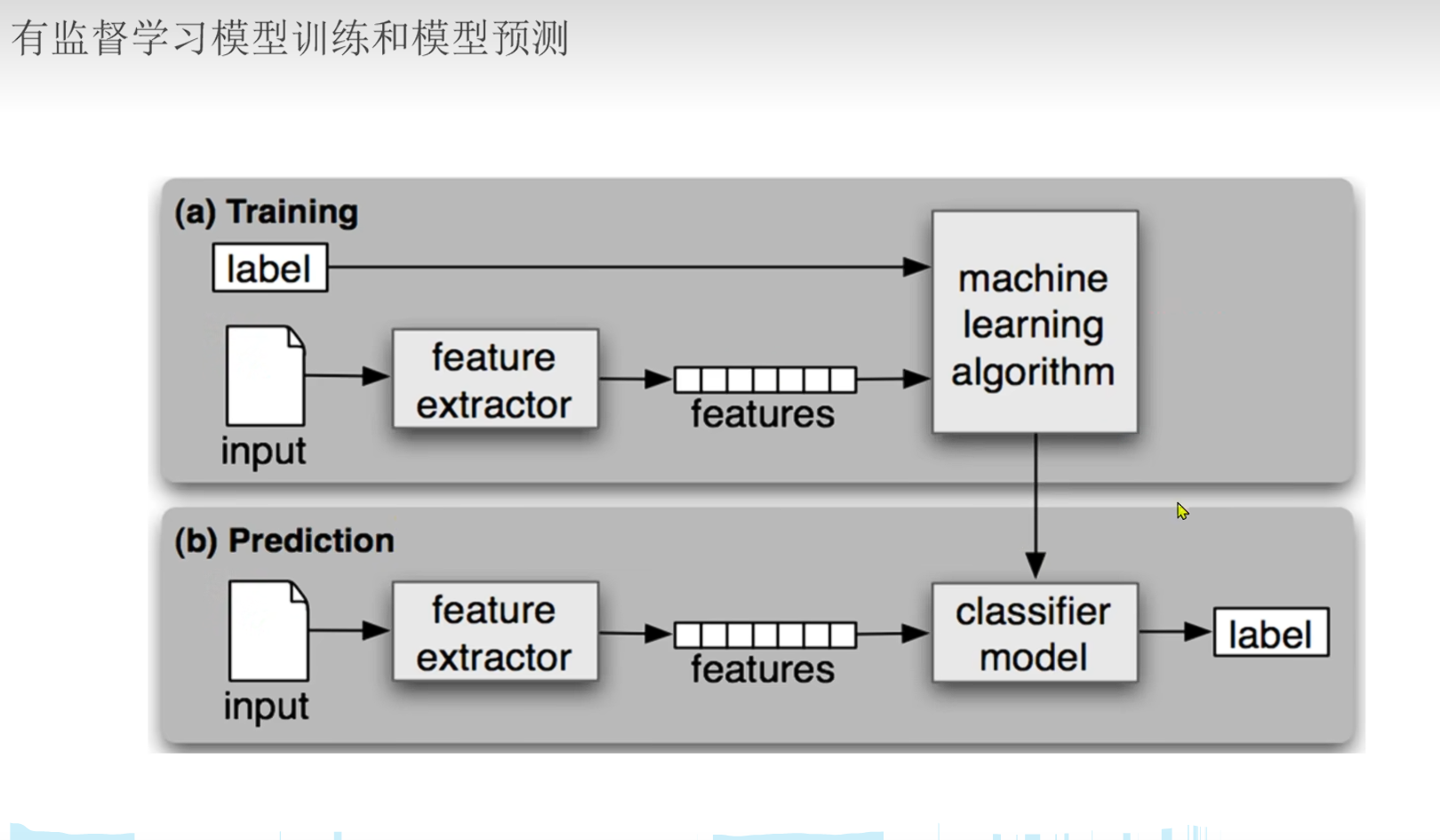
有监督学习: 训练数据包含输入和对应的输出,算法通过学习这些输入输出对来建立模型,以便对新的输入进行预测。
无监督学习: 训练数据只有输入,没有对应的输出,算法通过分析数据的结构和模式来发现隐藏的规律或分组。
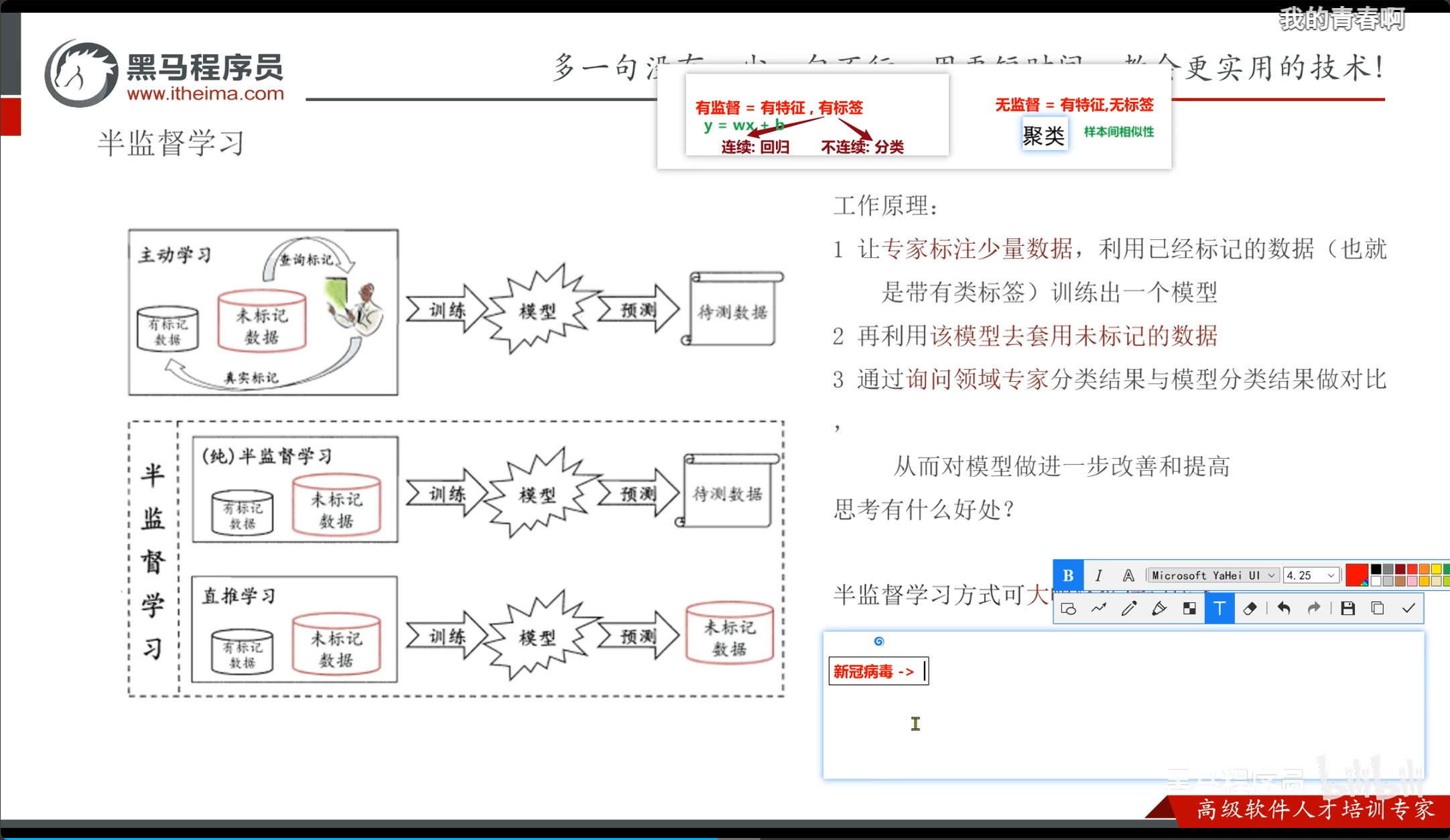
半监督学习: 训练数据包含少量的有标签数据和大量的无标签数据,算法通过利用有标签数据来指导无标签数据的学习,以提高模型的性能。
强化学习: 训练数据由智能体与环境的交互产生,算法通过试错和奖励机制来学习最优的行为策略,以最大化累积奖励。
距离度量
欧式距离: 对应特征值的差的平方和开根号 切比雪夫距离: 对应特征值的差的绝对值的最大值 曼哈顿距离: 对应特征值的差的绝对值的和
KNN算法
KNN: K近邻算法,K-Nearest Neighbors,是一种基本的分类和回归算法。它的核心思想是通过测量不同数据点之间的距离来进行分类或回归预测。对于一个新的数据点,KNN算法会找到训练集中与该数据点距离最近的K个邻居,然后根据这些邻居的类别或数值来进行预测。
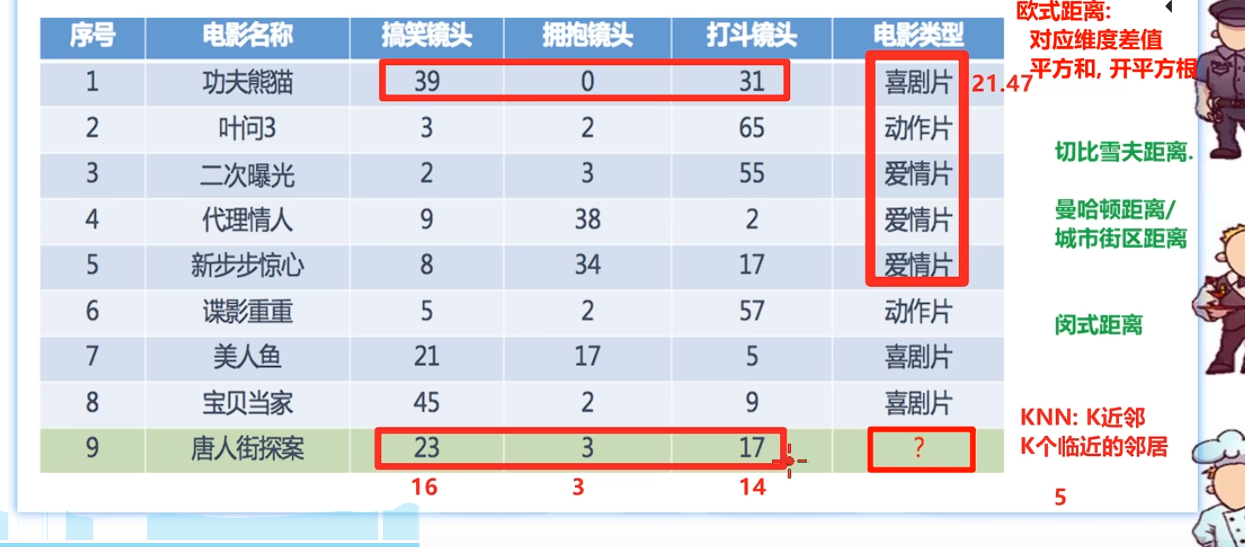
把电影看成 3 个特征向量:
唐人街探案 = (搞笑镜头 23,拥抱镜头 3,打斗镜头 17)
用 KNN 常用的欧氏距离:
[ d=\sqrt{(x_1-y_1)^2+(x_2-y_2)^2+(x_3-y_3)^2} ]
计算它到已有 8 部电影的距离:
| 电影 | 类型 | 差值 | 距离 |
|---|---|---|---|
| 功夫熊猫 | 喜剧片 | (16, 3, 14) | (\sqrt{461}=21.47) |
| 叶问3 | 动作片 | (20, 1, 48) | (\sqrt{2705}=52.01) |
| 二次曝光 | 爱情片 | (21, 0, 38) | (\sqrt{1885}=43.42) |
| 代理情人 | 爱情片 | (14, 35, 15) | (\sqrt{1646}=40.57) |
| 新步步惊心 | 爱情片 | (15, 31, 0) | (\sqrt{1186}=34.44) |
| 谍影重重 | 动作片 | (18, 1, 40) | (\sqrt{1925}=43.87) |
| 美人鱼 | 喜剧片 | (2, 14, 12) | (\sqrt{344}=18.55) |
| 宝贝当家 | 喜剧片 | (22, 1, 8) | (\sqrt{549}=23.43) |
按距离从小到大排序,最近的 3 个邻居是:
- 美人鱼:18.55,喜剧片
- 功夫熊猫:21.47,喜剧片
- 宝贝当家:23.43,喜剧片
如果取 K = 3,三个最近邻全都是喜剧片。
所以最后:
[ \boxed{唐人街探案 \rightarrow 喜剧片} ]
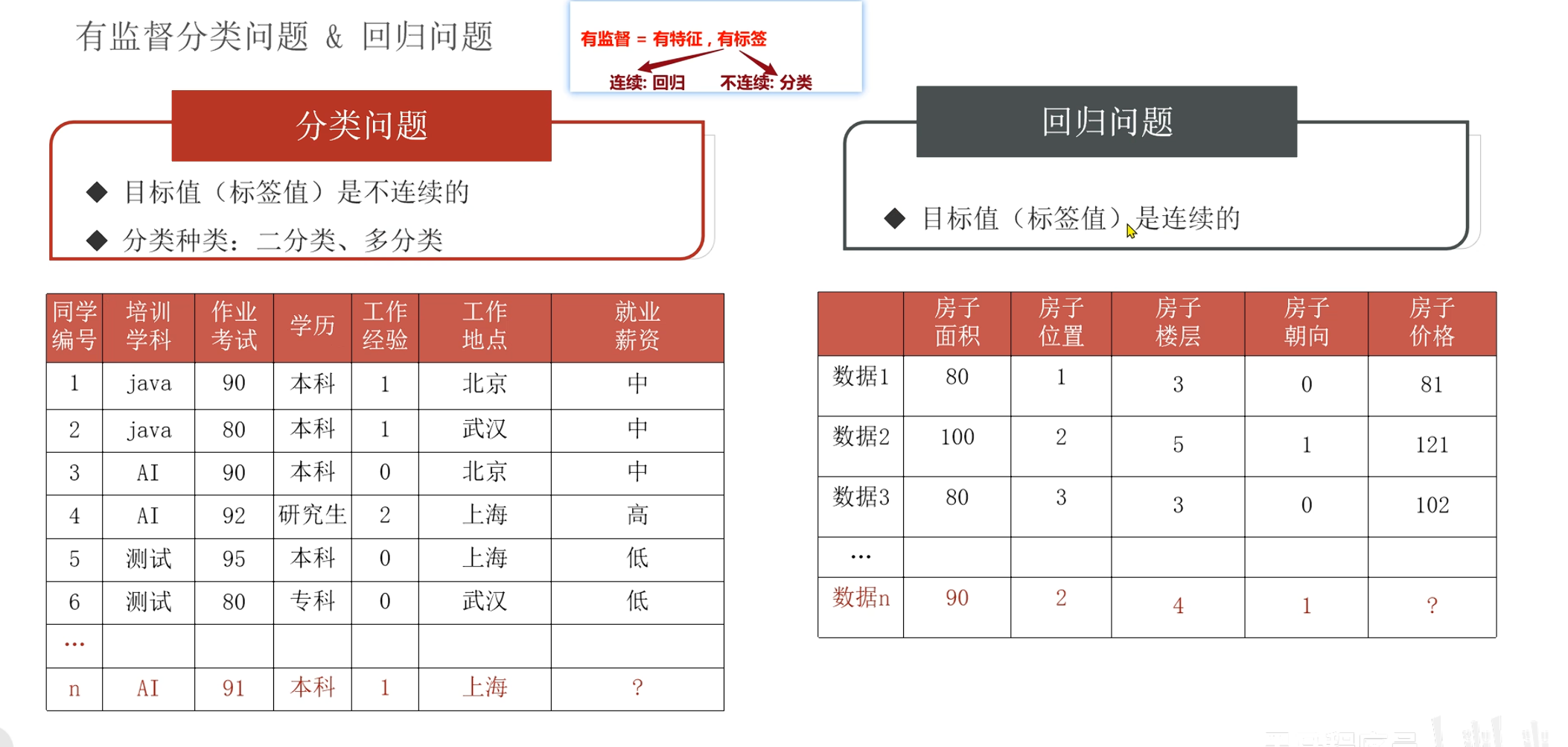
分类回归问题
分类问题:KNN 可以用来进行分类预测。对于一个新的数据点,KNN 会找到训练集中与该数据点距离最近的 K 个邻居,然后根据这些邻居的类别来进行预测。通常使用多数投票的方式,即选择 K 个邻居中出现频率最高的类别作为预测结果。
回归问题:KNN 也可以用于回归预测。对于一个新的数据点,KNN 会找到训练集中与该数据点距离最近的 K 个邻居,然后根据这些邻居的数值来进行预测。通常使用平均值的方式,即计算 K 个邻居的数值的平均值作为预测结果。
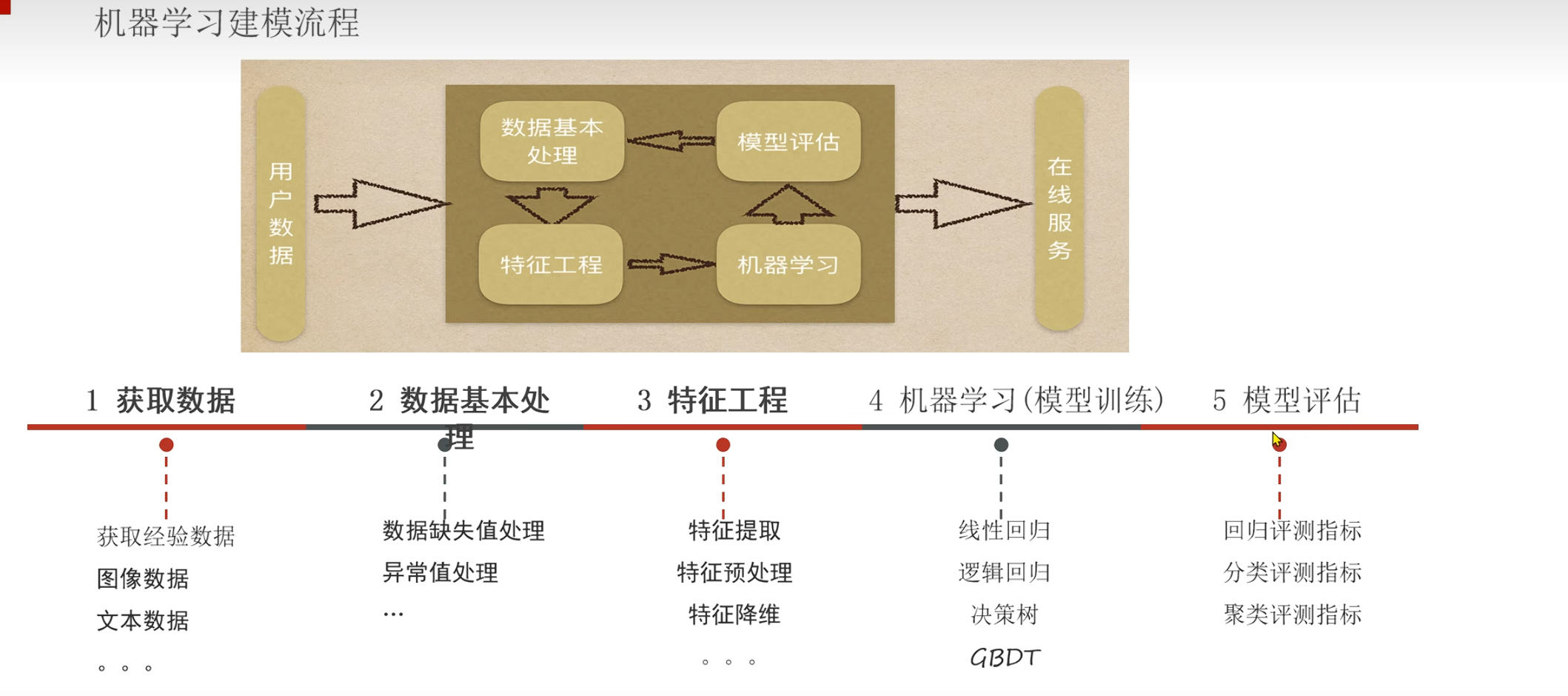
机器学习建模流程
用户数据 -> 数据基本处理 -> 特征工程 -> 机器学习 -> 模型评估 -> 数据基本处理 -> 特征工程 -> 机器学习 -> 模型评估 -> 数据基本处理 -> 特征工程 -> 机器学习 -> 模型评估 -> … -> 模型上线

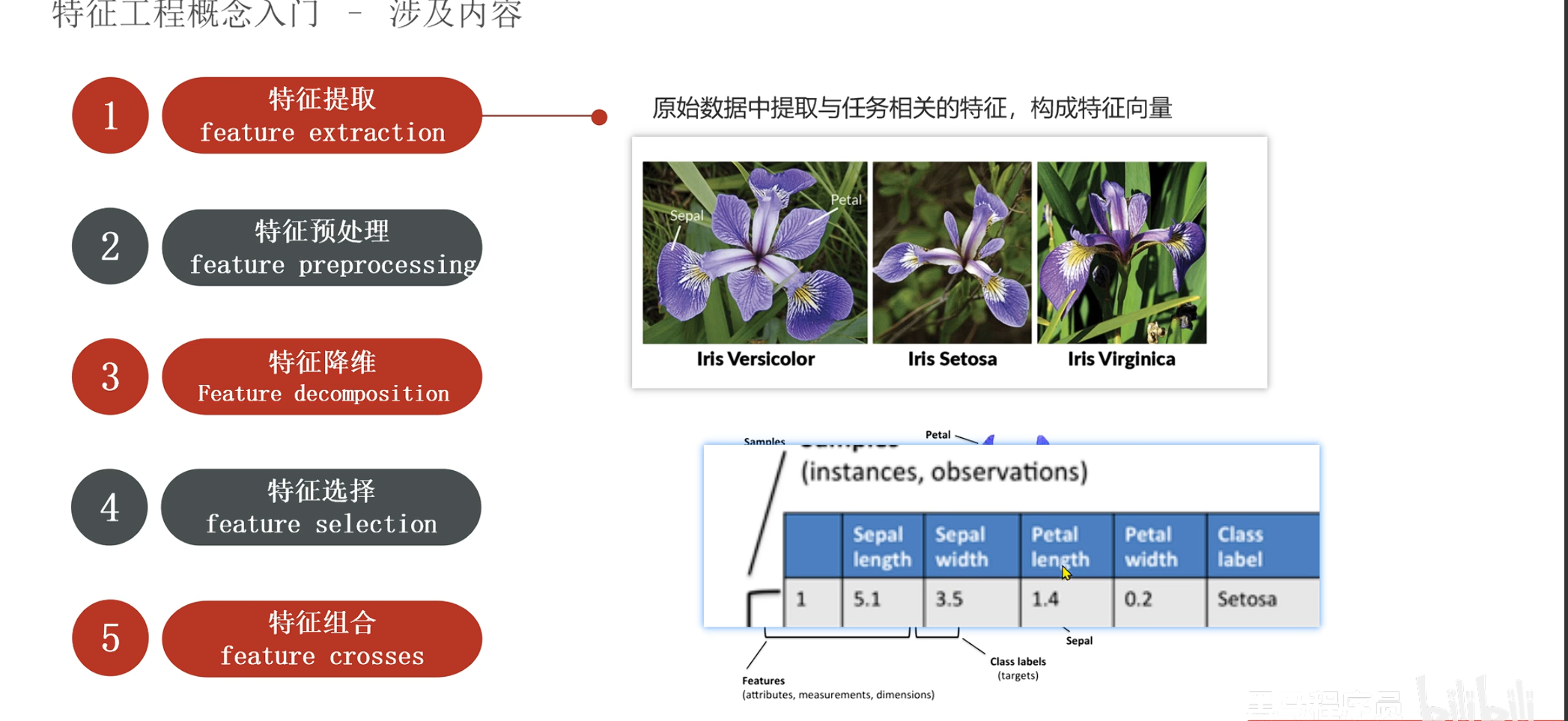
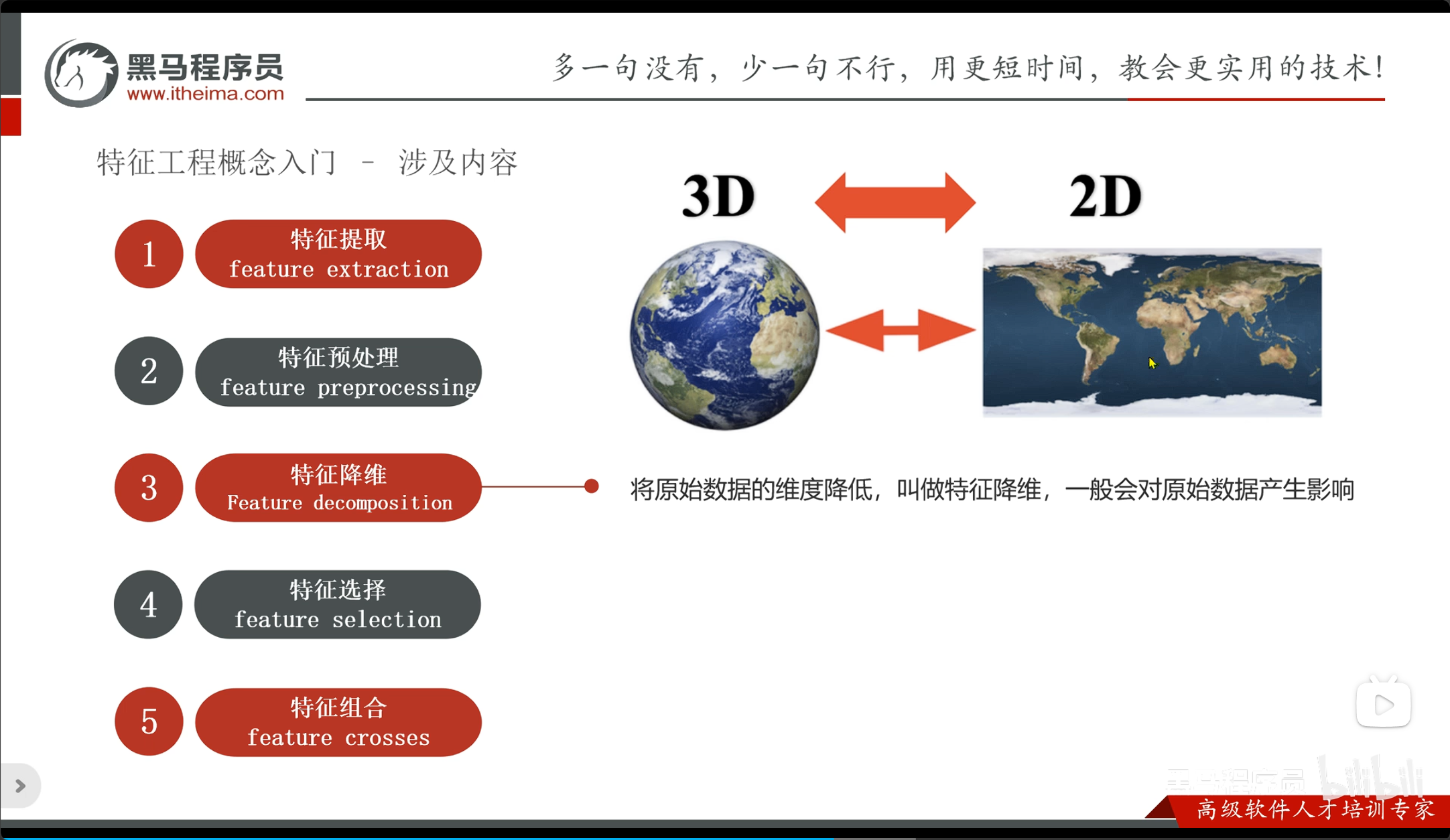
特征工程相关概念

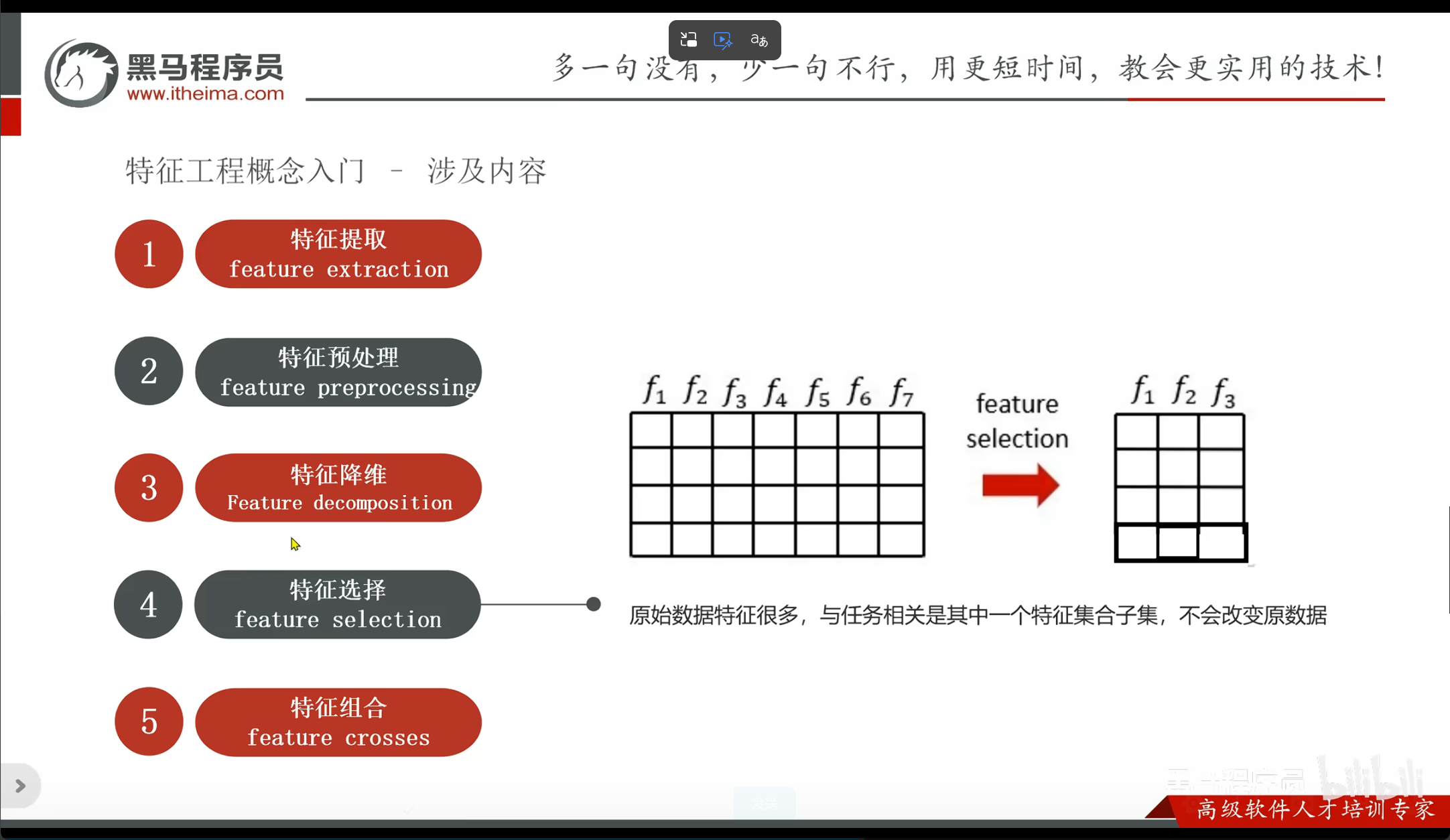
提取流程
特征提取 -> 特征预处理 -> 特征降维 -> 特征选择 -> 特征组合

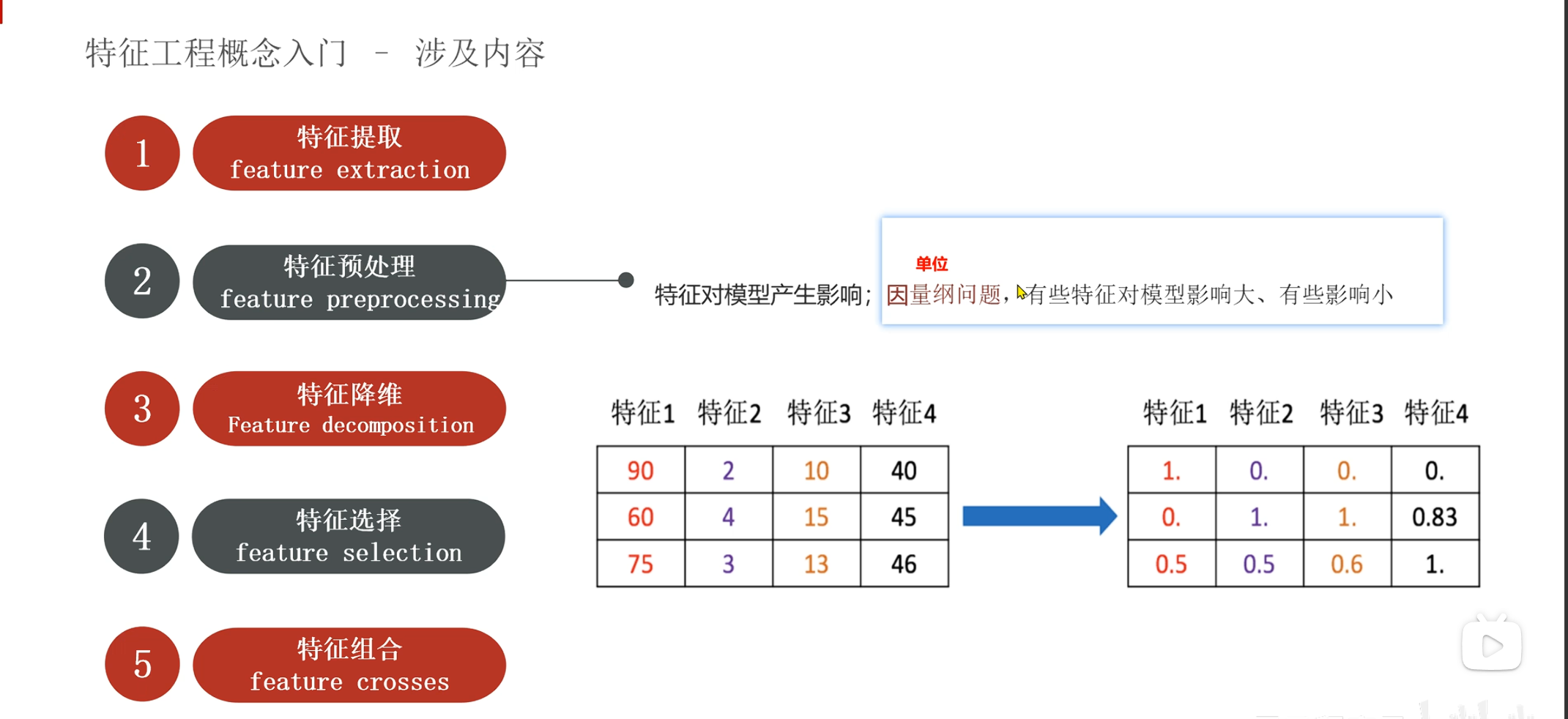
特征预处理
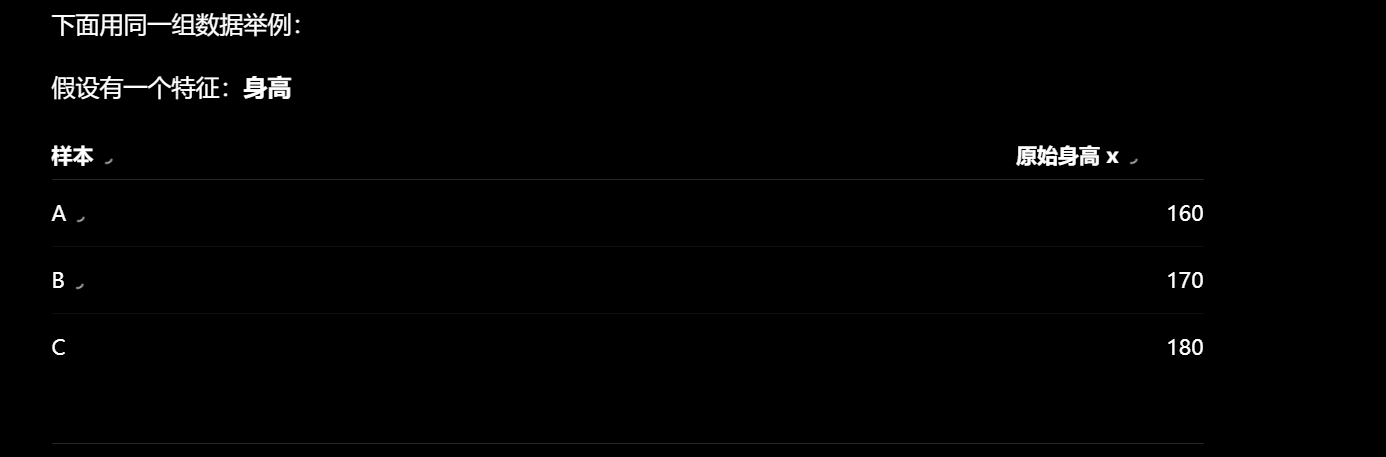
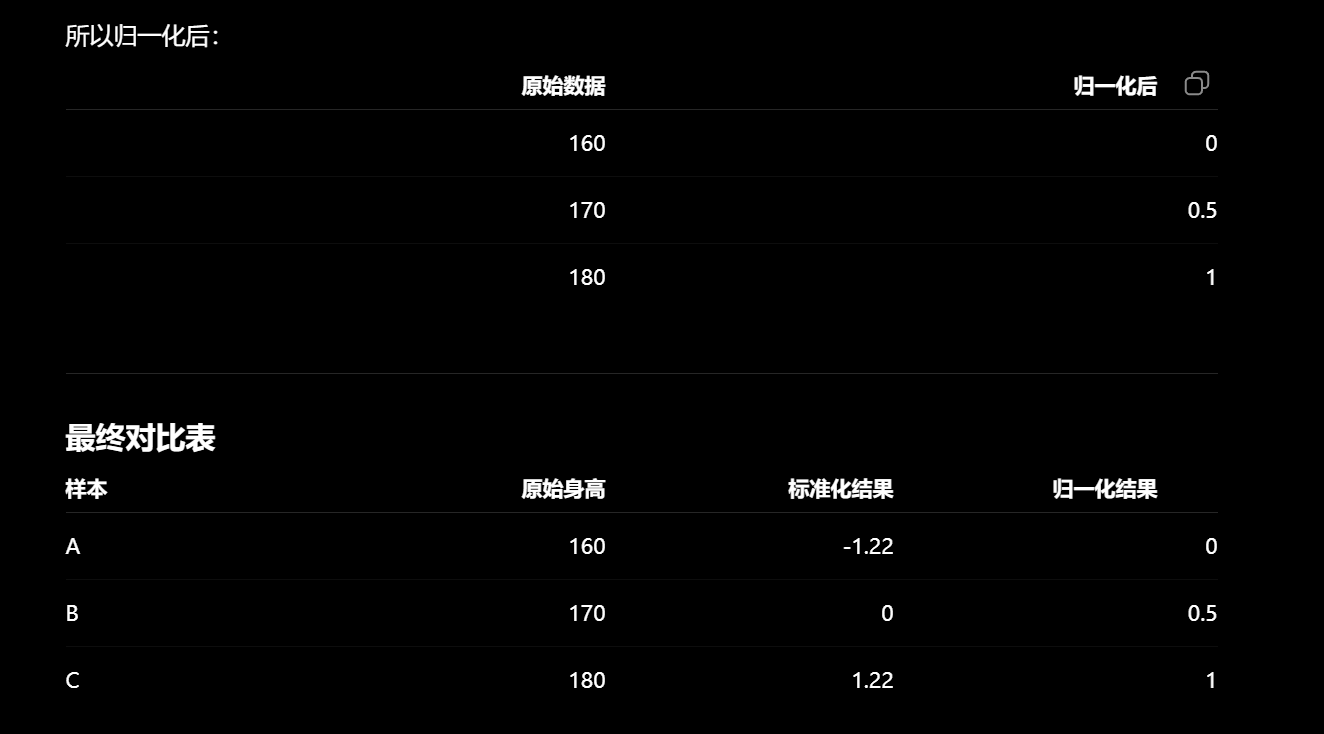
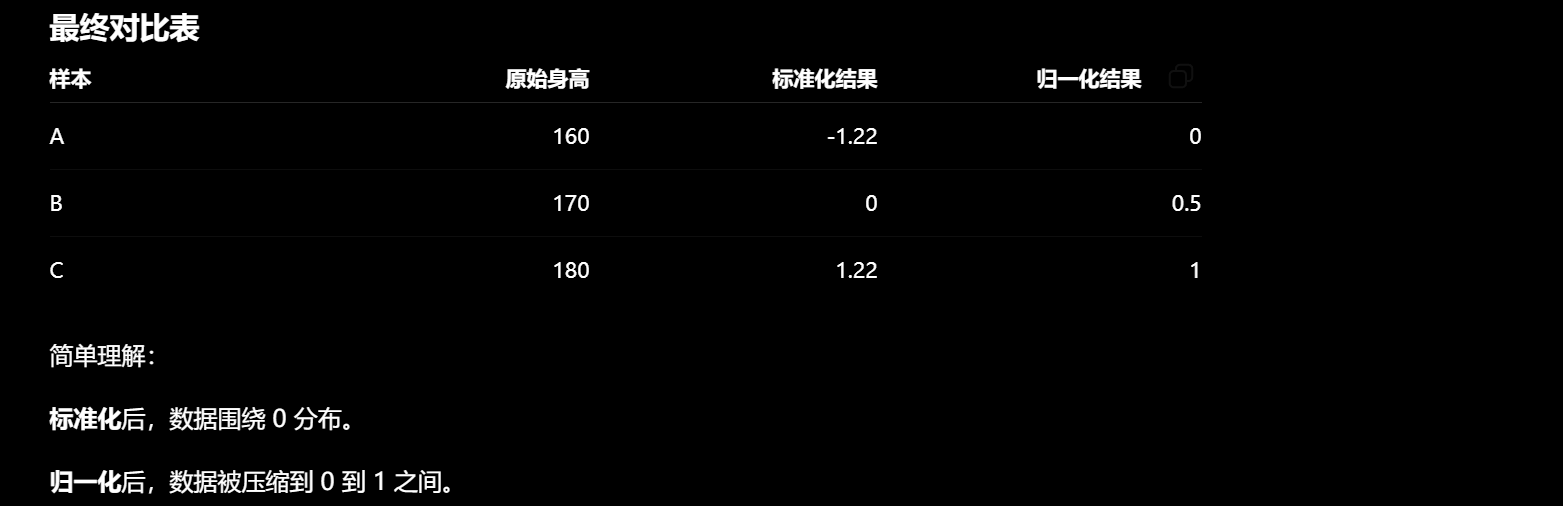
特征预处理: 两种方法: 归一化和标准化
归一化 (Normalization):把数据平移压缩到 [0, 1] 的固定区间内。 (当前值-最小值)/ (最大值 - 最小值) 标准化 (Standardization):把数据变成均值为 0,标准差为 1 的分布(去中心化) (当前值 - 均值) / 标准差。





特征降维
特征降维

特征选择
特征组合

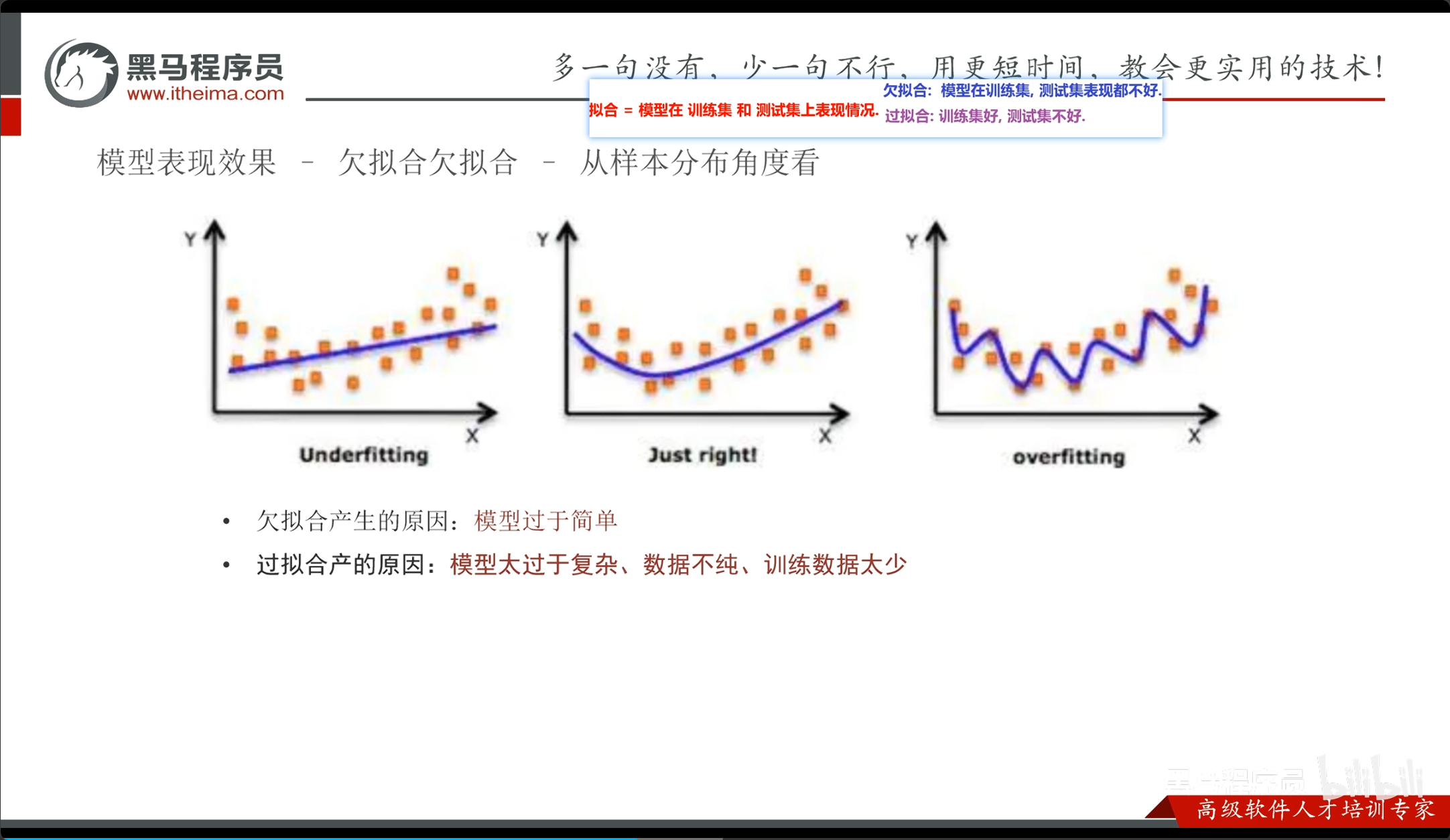
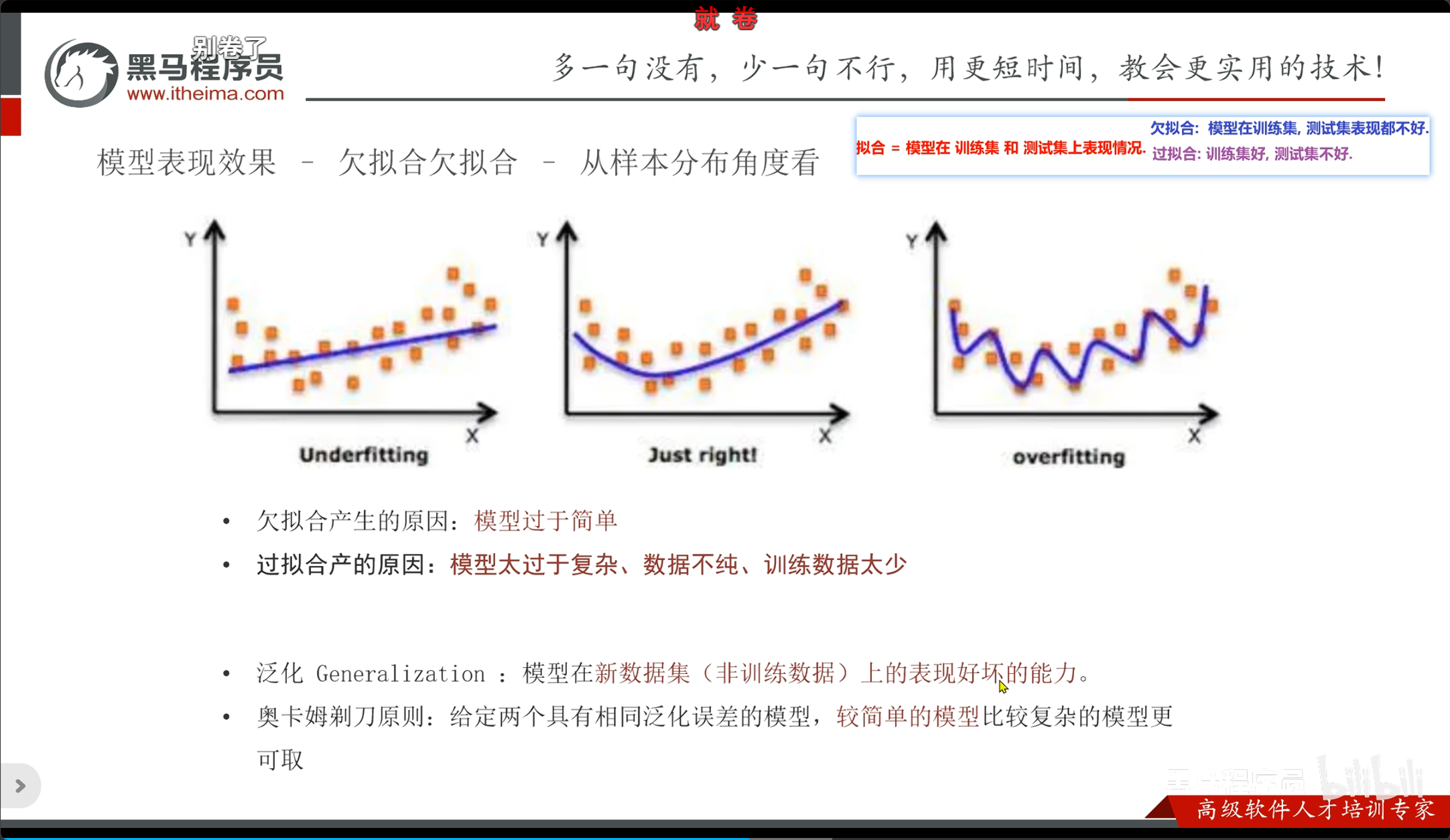
模型拟合


发现错误或想要改进这篇文章?
在 GitHub 上编辑此页RSS / 网站地图
由 Astro 和 Fuwari 强力驱动
本网站代码 已开源 (41fa9b4 @ 2026-07-06 00:42:04)
 晋ICP备2025071728号-1
晋ICP备2025071728号-1  晋公网安备14060202000213号
晋公网安备14060202000213号