
什么是 KNN 算法?
KNN(K-Nearest Neighbors,K近邻算法) 是一种基础且易于理解的机器学习算法。它可以用于分类(Classification)和回归(Regression)问题。
KNN 的核心思想可以用一句中国古话来概括:“近朱者赤,近墨者黑”。 它的工作原理是:给定一个未知的样本,算法会在训练集中寻找与该样本距离最近(最相似)的 K 个样本。然后:
- 如果是分类任务:采用“少数服从多数”的原则,这 K 个邻居中哪种类别最多,就把未知样本归为该类别。
- 如果是回归任务:计算这 K 个邻居的目标值的平均值,作为该未知样本的预测值。
NOTEKNN 是一种**惰性学习(Lazy Learning)**算法。它在训练阶段几乎不做任何计算,只是把训练数据“存起来”。所有的计算(算距离、排序)都推迟到了预测阶段。
KNN 计算过程与算分示例
要衡量“谁离我最近”,我们需要一个距离度量。最常用的是欧氏距离(Euclidean Distance)。 对于二维平面上的两个点 和 ,它们的欧氏距离公式为:
举个栗子:水果分类
假设我们有一个根据“重量(g)”和“红度(0-10)”来分辨苹果(Apple)和橙子(Orange)的数据集。
| 水果编号 | 重量 (X) | 红度 (Y) | 种类 (Label) |
|---|---|---|---|
| 1 | 150 | 8 | 苹果 |
| 2 | 160 | 9 | 苹果 |
| 3 | 170 | 3 | 橙子 |
| 4 | 180 | 4 | 橙子 |
新来了一个未知水果点 P,重量为 158g,红度为 7。它是苹果还是橙子?
第一步:计算距离 我们计算 P(158, 7) 到所有已知数据的距离。
- 到水果 1 的距离:
- 到水果 2 的距离:
- 到水果 3 的距离:
- 到水果 4 的距离:
第二步:排序并选出 K 个最近的邻居 距离从小到大排序为:
- 水果 2 (, 苹果)
- 水果 1 (, 苹果)
- 水果 3 (, 橙子)
- 水果 4 (, 橙子)
第三步:投票决定类别
- 如果设定 :最近的邻居是水果 2(苹果),所以 P 预测为苹果。
- 如果设定 :距离最近的三个邻居分别是 [水果2(苹果), 水果1(苹果), 水果3(橙子)]。经过投票,2票比1票,所以 P 还是苹果。
K 值的影响
在 KNN 算法中, 的取值至关重要,它是该算法的核心超参数(Hyperparameter)。
1. K 值过小(例如 K=1)
-
特点:模型只看最近的那一个点,极度敏感。
-
影响:容易受到噪声数据和异常值的干扰,引起模型的过拟合(Overfitting)。
-
现象:在训练集上表现很好(甚至100%正确),但在测试集上表现很差,决策边界极其扭曲复杂。
2. K 值过大(例如 K=N,N为样本总数)
-
特点:相当于把所有的点都拿来投票。
-
影响:无论输入什么样本,模型总是预测为训练集中样本数量最多的那个类别,导致欠拟合(Underfitting)。
-
现象:模型过于简单,无法学习到数据的真实模式,决策边界变得平滑甚至消失。
3. 如何选择合适的 K 呢?
- 交叉验证(Cross-Validation):通常会尝试从 K=1 开始,递增 K 测试误差(比如1, 3, 5, 7, 9…),选择在验证集上错误率最低的那个 K。
- 通常选奇数:在二分类问题中,K 通常被设置为奇数(如 3, 5, 7),以避免出现 2:2 投票平局的尴尬情况。
- 经验法则:行业内一种常见的初始拇指法则是将 K 设置为训练样本总数的平方根()。
总结
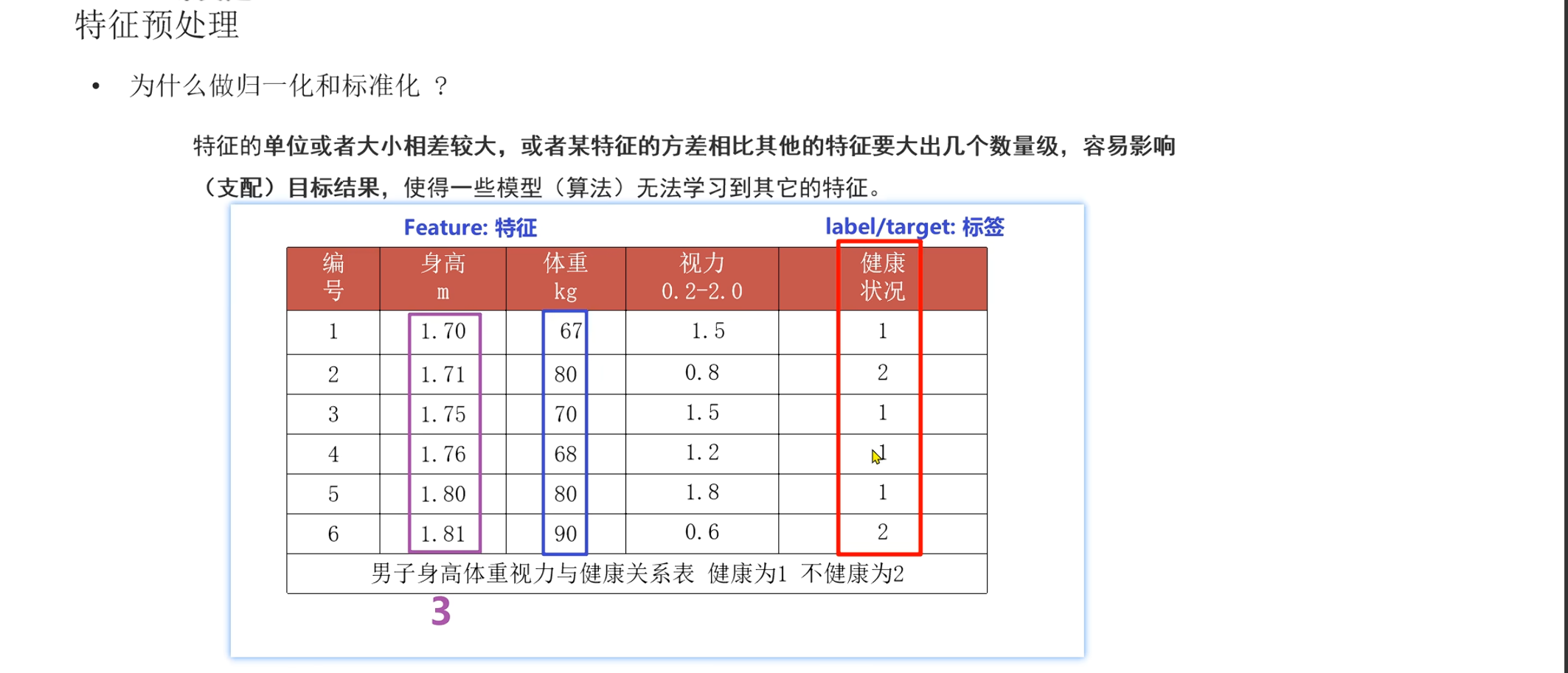
KNN 是一种无需复杂数学推导、思想直观的算法。虽然它的训练速度极快,但在预测时需要计算大量数据距离,因此在数据集极大或特征维度过高时(维度灾难),计算代价会变得非常昂贵。实际应用中,常常需要先对数据进行归一化/标准化处理,以免某些大数值的特征“吃掉”了较小数值特征影响。
KNN解决问题的两种思维
分类和回归都属于有监督学习。对于这两种任务,KNN 在寻找完邻居后,最后一步“做决定”时的逻辑有所不同:

分类问题 (Classification)
- 应用场景:预测离散的类别标签。例如:判断一封邮件是否为垃圾邮件、判断新出现的病症是良性还是恶性等。
- 决策规则:多数表决机制(Majority Voting)
- 具体做法:在计算距离并找到距离最近的 个邻居后,统计这些邻居所属的类别数量。哪个类别出现的次数最多(得票最多),该未知样本就被判定为哪个类别。(这就是前面苹果和橙子例子中的思维)。
- 举个例子:假设我们想判断一部电影是“动作片”还是“爱情片”。如果设置 ,我们找到距离这部未知电影最近的 5 部电影。如果结果是 [动作片, 动作片, 动作片, 爱情片, 爱情片]。因为 3 票 > 2 票,所以这部未知电影会被分类为动作片。
- 进阶:如果投票出现平局,通常可以通过引入**距离加权(Distance Weighting)**来解决:距离越近的邻居,其选票的权重占得越大。
回归问题 (Regression)
- 应用场景:预测连续的数值。例如:预测某套房子的具体价格、预测这只股票明天的价格等。
- 决策规则:求平均值(Averaging)
- 具体做法:在找到距离最近的 个邻居后,将这 个邻居的目标数值加起来求平均值。算出来的这个平均结果,就是模型对未知样本的数值预测结果。
- 举个例子:假设我们想预测一套面积为 的房子的价格。如果设置 ,我们找到了 3 套和它各项特征最相似的房子,它们的价格分别是 [150万, 155万, 145万]。那么这套房子的预测价格就是: 万。
- 进阶:同理,在回归计算中也可以使用距离加权平均,让距离更近的邻居所在的数值对最终结果产生更大的影响。
KNN API算法实现
在实际应用中,我们通常会使用机器学习库(如 scikit-learn)来实现 KNN 算法。以下是一个简单的示例,展示如何使用 scikit-learn 来进行分类和回归任务:
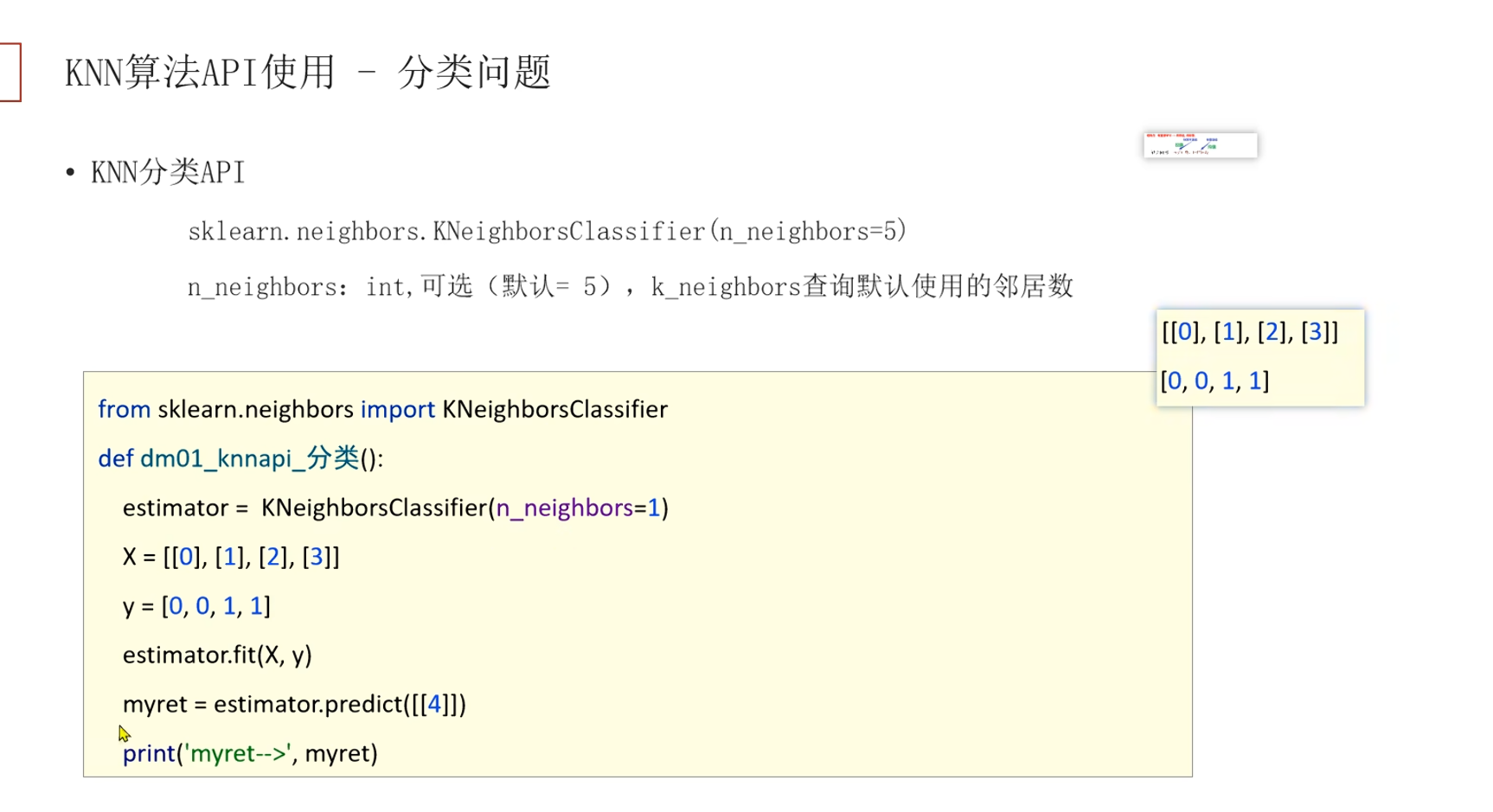
"""KNN 分类最小示例"""from sklearn.neighbors import KNeighborsClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler
# 1. 加载数据data = load_iris()# x 是特征矩阵,y 是标签向量X, Y= data.data, data.target
# 2. 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split( X, Y, test_size=0.3, random_state=42)
# 3. 标准化(KNN 依赖距离计算,需要统一量纲)scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
# 4. 训练 KNNknn = KNeighborsClassifier(n_neighbors=5)knn.fit(X_train, y_train)
# 5. 预测 + 评估y_pred = knn.predict(X_test)acc = knn.score(X_test, y_test)
print(f"KNN(k=5) 准确率: {acc:.2%}\n")
# 6. 打印预测结果对比target_names = load_iris().target_namesprint("真实类别 -> 预测类别")print("-" * 25)for true, pred in zip(y_test[:20], y_pred[:20]): print(f" {target_names[true]:10s} -> {target_names[pred]:10s}")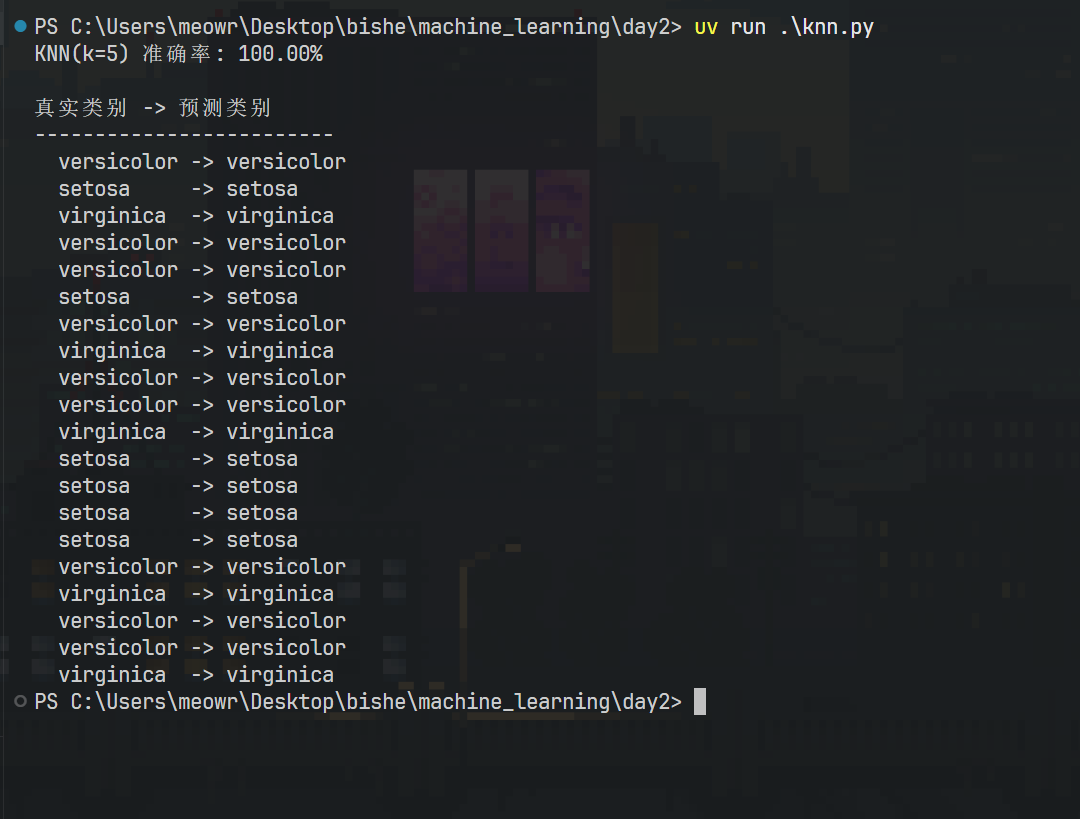
"""KNN 回归示例 — 用糖尿病病情数据预测"""from sklearn.neighbors import KNeighborsRegressorfrom sklearn.datasets import load_diabetesfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler
# 1. 加载真实数据(442名糖尿病患者的10项指标)data = load_diabetes()X, y = data.data, data.targetprint(f"特征: {data.feature_names}")print(f"样本数: {X.shape[0]}, 特征数: {X.shape[1]}")
# 2. 划分X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=42)
# 3. 标准化scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
# 4. 训练 KNN 回归knn = KNeighborsRegressor(n_neighbors=5)knn.fit(X_train, y_train)
# 5. 预测 + 评估y_pred = knn.predict(X_test)r2 = knn.score(X_test, y_test)
print(f"KNN Regression (k=5) R2 Score: {r2:.4f}")print("\n真实病情指标 -> 预测病情指标")print("-" * 35)for true, pred in zip(y_test[:10], y_pred[:10]): print(f" {true:6.1f} -> {pred:6.1f}")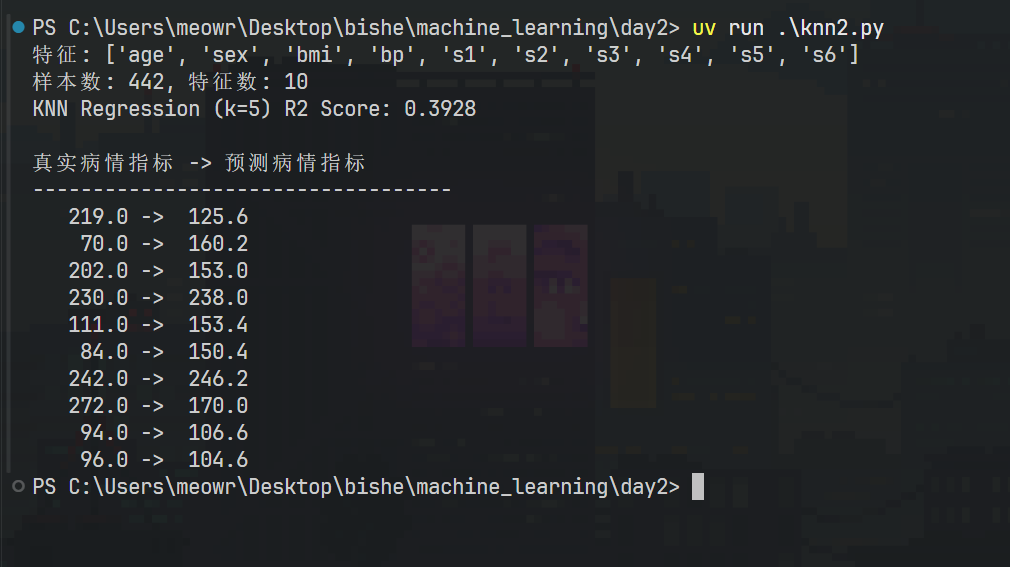
特征预处理


"""KNN 分类最小示例"""from sklearn.neighbors import KNeighborsClassifierfrom sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import MinMaxScaler
# 1. 加载数据data = load_iris()# x 是特征矩阵,y 是标签向量X, Y= data.data, data.target
# 2. 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split( X, Y, test_size=0.3, random_state=42)
# 3. 标准化(KNN 依赖距离计算,需要统一量纲)scaler = MinMaxScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
# 4. 训练 KNNknn = KNeighborsClassifier(n_neighbors=5)knn.fit(X_train, y_train)
# 5. 预测 + 评估y_pred = knn.predict(X_test)acc = knn.score(X_test, y_test)
print(f"KNN(k=5) 准确率: {acc:.2%}\n")
# 6. 打印预测结果对比target_names = load_iris().target_namesprint("真实类别 -> 预测类别")print("-" * 25)for true, pred in zip(y_test[:20], y_pred[:20]): print(f" {target_names[true]:10s} -> {target_names[pred]:10s}")这个代码用了归一化,上面knn的代码用了标准化。
利用KNN算法对鸢尾花进行分类

'''利用KNN算法对鸢尾花进行分类'''
from sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn.datasets import load_irisimport pandas as pdfrom sklearn.preprocessing import StandardScaler
data = load_iris()print(f"特征: {data.feature_names}")print(f"样本数: {data.data.shape[0]}, 特征数: {data.data.shape[1]}")print(f"类别: {data.target_names}")
'''打印鸢尾花数据集的前5行(包括特征和标签) 表格形式'''
df = pd.DataFrame(data.data[:20], columns=data.feature_names)df['target'] = [data.target_names[i] for i in data.target[:20]]print(df)
X_train,X_test,y_train,y_test = train_test_split( data.data, data.target, test_size=0.3, random_state=42)
# 标准化scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
knn = KNeighborsClassifier(n_neighbors=5)knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)acc = knn.score(X_test, y_test)
print("=" * 30)print(f"KNN(k=5) 准确率: {acc:.2%}\n")print("真实类别 -> 预测类别")print("-" * 25)for true, pred in zip(y_test[:20], y_pred[:20]): print(f" {data.target_names[true]:10s} -> {data.target_names[pred]:10s}")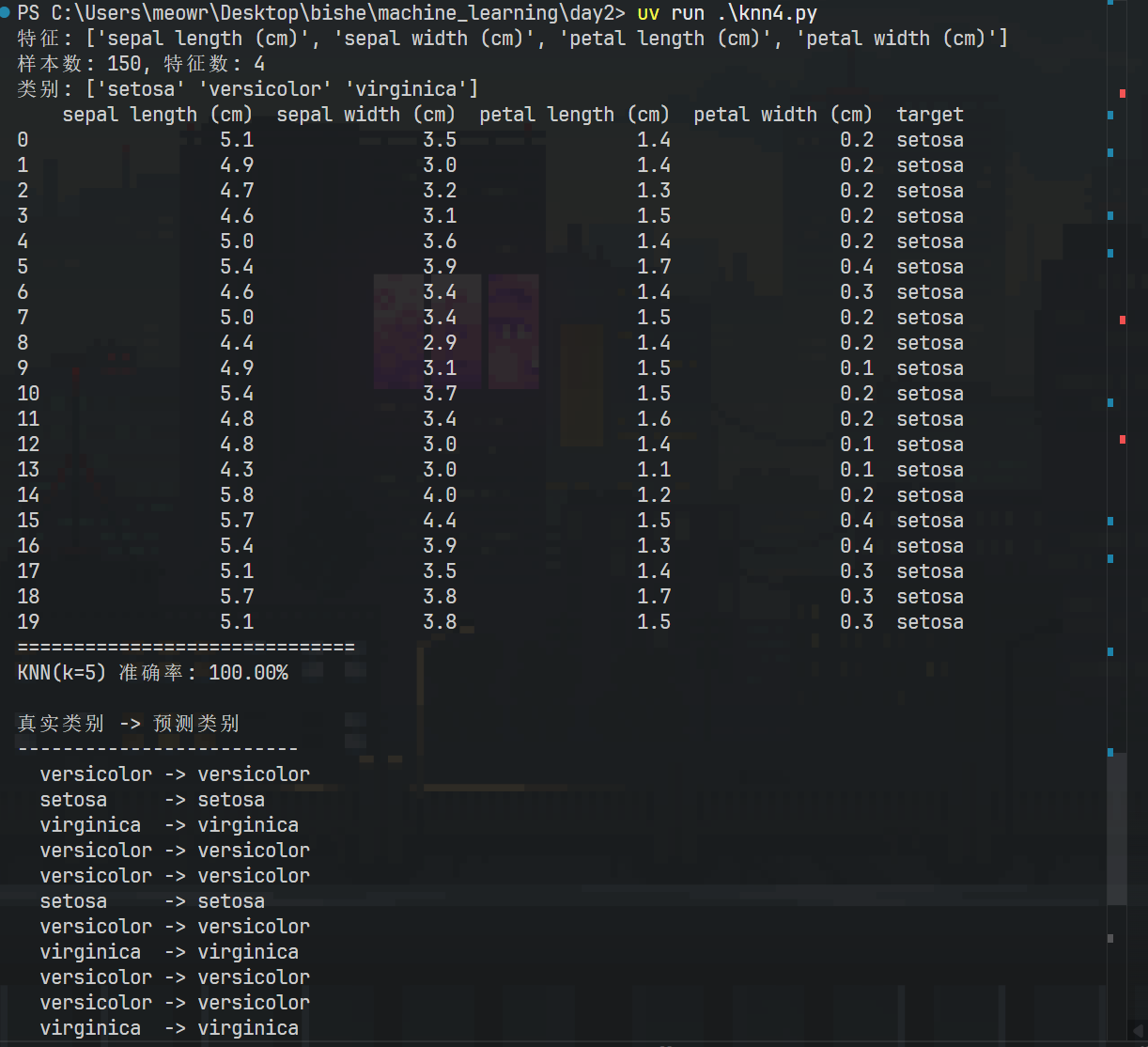
模型超参数调优与交叉验证
基于以上基础,在实际的机器学习工作流中,我们更希望能让机器“自动”找出最好的 K 值,而不是像上面那样写死为 k=5,以下步骤就是专门解决这个问题的进阶应用:
1. 知道交叉验证是什么?

交叉验证(Cross-Validation)是一种用于评估模型泛化能力并防止模型因特定数据分布偶然偏差而过拟合的方法。 最常用的是 K折交叉验证(K-Fold Cross-Validation)。
- 原理:将原始训练集随机划分成 个大小相等的子集(称为“折”,fold)。
- 过程:每次选择其中 1 个子集作为验证集,剩下的 个子集作为训练集。这个过程重复 次,每个子集都有一次机会作为验证集。
- 结果:最终的模型评估指标是这 次验证结果的平均值。这能降低单次划分带来的运气成分,让模型评估更加稳定、客观。
2. 知道网格搜索是什么?
网格搜索(Grid Search)是一种通过穷举遍历给定的所有参数组合,来寻找模型最优超参数(Hyperparameters,如 K临近算法里的 值大小)的最简单粗暴的方法。
- 原理:当我们有多个超参数需要调优(比如不仅要找最佳的
n_neighbors,还想探讨算法是使用欧式距离还是曼哈顿距离p等),我们可以为每个超参数设定一个候选值列表。 - 过程:网格搜索会将这些参数列表组合成一个“多维网格”,然后对网络里的每一组参数设定,都训练一个模型并评估其性能。
- 结果:对比得出到底在交叉验证中取得最高得分的那组“超参数组合”是什么。
3. 交叉验证网格搜索API函数用法
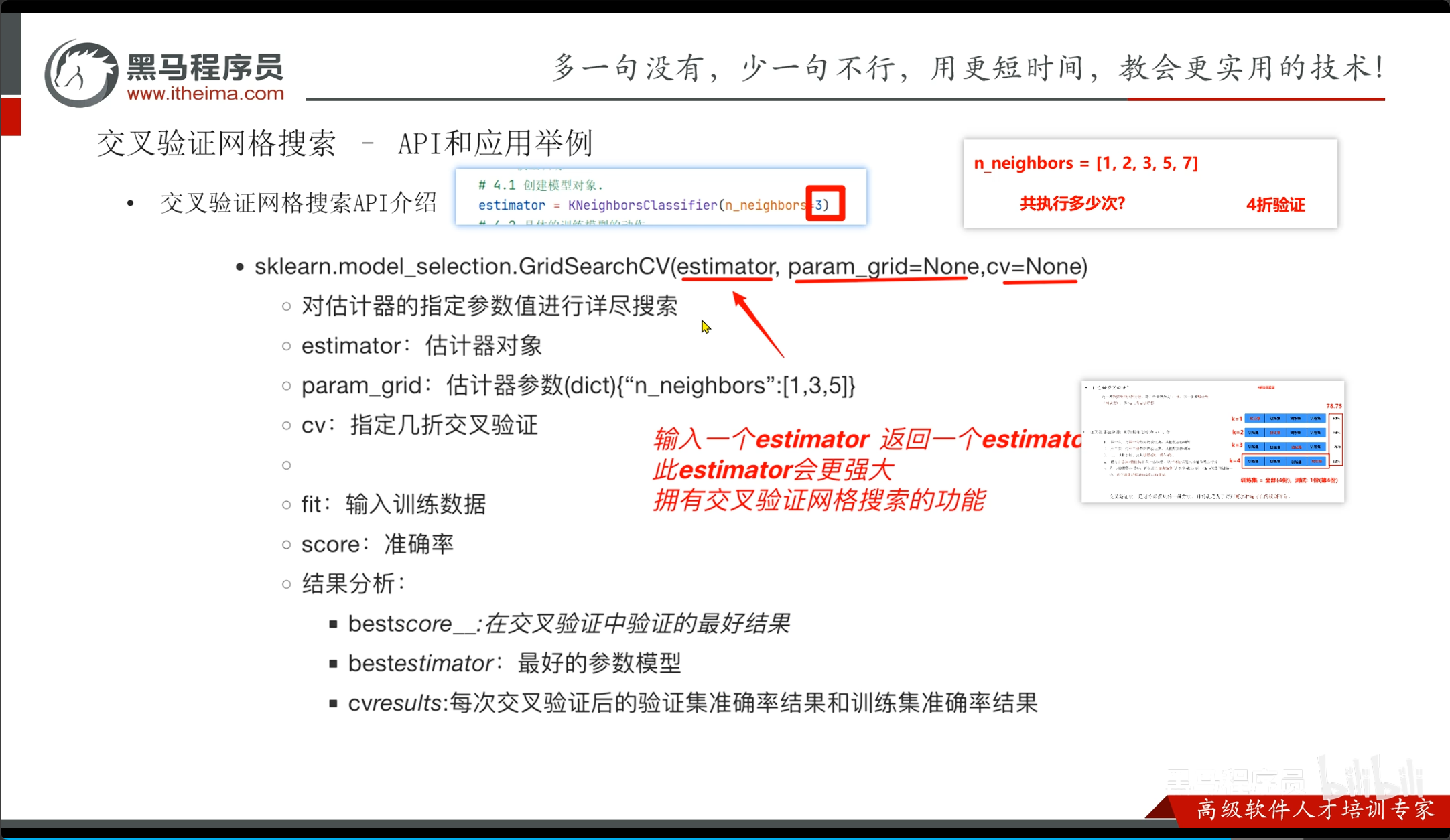
在 scikit-learn 中,将二者结合使用的 API 为 GridSearchCV。通过这一个函数,我们就能写出既能网格搜索寻找不同组合,又能自动进行K折交叉验证打分的最优质代码。
其基本用法如下:
from sklearn.model_selection import GridSearchCVfrom sklearn.neighbors import KNeighborsClassifier
# 1. 初始化我们要用的模型框架knn = KNeighborsClassifier()
# 2. 定义你想搜索的超参数“网格”(必须是字典格式)# 比如探讨 K值 取 1 到 11 之间哪个表现最好param_grid = { 'n_neighbors': [1, 3, 5, 7, 9, 11]}
# 3. 实例化 GridSearchCV# estimator: 模型算法估计器# param_grid: 搜索的参数网格字典# cv: K折交叉验证的折数(比如 cv=5 表示5折交叉验证)gs = GridSearchCV(estimator=knn, param_grid=param_grid, cv=5)
# 4. 训练模型并搜索最优参数# gs.fit(X_train, y_train)
# 5. 获取结果(在被 fit 后这些属性才会有相应的值)# 最佳估计器模型: gs.best_estimator_# 交叉验证中的最高平均得分: gs.best_score_# 促使这一最高得分发生的最优参数组: gs.best_params_# 如果你要细看交叉验证的每一次得分明细: gs.cv_results_4. 实践:交叉验证网格搜索进行模型超参数调优
让我们基于上面的鸢尾花分类进行升级改造,加入网格搜索机制,来自动寻找使得预测模型最精准的最佳的 K 值:

from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsClassifier
# 1. 准备数据并划分data = load_iris()X_train, X_test, y_train, y_test = train_test_split( data.data, data.target, test_size=0.3, random_state=42)
# 2. 数据标准化(确保在同一个空间度量尺度下计算)scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
# 3. 准备模型及需要调优的候选参数knn = KNeighborsClassifier()param_grid = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
# 4. 启动交叉验证网格搜索(本例采用5折)gs = GridSearchCV(knn, param_grid=param_grid, cv=5)gs.fit(X_train, y_train)
# 5. 打印调优反馈print(f"交叉验证里的最佳分数: {gs.best_score_:.4f}")print(f"找到的最优参数: {gs.best_params_}")
# 6. 直接拿出选出的“考第一名”的模型放到测试集里进行最后的摸底能力测试best_knn = gs.best_estimator_acc = best_knn.score(X_test, y_test)print(f"它在最终新样本测试集上的脱产准确率: {acc:.4f}")5. 利用KNN算法实现手写数字识别
在机器学习界,手写数字识别任务(判断 0-9)是一项经典的综合类实践。
通常可以利用 scikit-learn 自带的小型 digits 数据集,该库包含近1800张 的低清数字图片矩阵像素点数据(拉平了就是长度为 64 的像素特征列)。
下面的代码展示了从载入图片数据集,到进行网格搜素选取 KNN 模型最优状态,并进行准确率预测的一条完整链路:
import matplotlib.pyplot as pltfrom sklearn.datasets import load_digitsfrom sklearn.model_selection import train_test_split, GridSearchCVfrom sklearn.preprocessing import StandardScalerfrom sklearn.neighbors import KNeighborsClassifier
# 1. 加载手写数字数据集digits = load_digits()X = digits.data # 形状为 (1797行样本, 64列特征像素) 的特征二维数组y = digits.target # 形状为 (1797,) 的对应标签数组(0-9这十个数字)
print(f"数据集大小: {X.shape}")
# ---- (可选展示) 画出其第一张手写数字长什么样子 ----# plt.gray()# plt.matshow(digits.images[0])# plt.show()# ---------------------------------------------------
# 2. 划分数据集 (抽出 25% 留作期末测试,75% 用以训练调优)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42)
# 3. 数据标准化 (对于像素级分布有差异的数据,标准化能加速距离计算并提高精度)scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
# 4. 定义模型,并构建包含了多个调优超参数组合字典的网格knn = KNeighborsClassifier()param_grid = { 'n_neighbors': [3, 5, 7, 9], 'weights': ['uniform', 'distance'], # uniform是平均权重距离,distance是距离越近投票权重越大 'p': [1, 2] # 1是曼哈顿距离估算计算,2是经典的欧式平滑直线距离}
# 采取3折交叉验证,n_jobs=-1 意义为火力全开使用CPU所有线程进行并发网格搜索训练gs = GridSearchCV(knn, param_grid=param_grid, cv=3, n_jobs=-1)print("正在进行 KNN 网格搜索与参数调优,请稍候...")gs.fit(X_train, y_train)
# 5. 输出模型被验证器挑选出的结果与最高性能评分评估print(f"打分最高的最佳超参数组合: {gs.best_params_}")print(f"这套组合下的交叉验证训练场得分: {gs.best_score_:.4f}")
# 6. 使用第一名优秀参数模型前往完全未知新环境进行抗压摸底考核best_model = gs.best_estimator_test_acc = best_model.score(X_test, y_test)print(f"测试集准确率: {test_acc:.4f}")发现错误或想要改进这篇文章?
在 GitHub 上编辑此页RSS / 网站地图
由 Astro 和 Fuwari 强力驱动
本网站代码 已开源 (41fa9b4 @ 2026-07-06 00:42:04)
 晋ICP备2025071728号-1
晋ICP备2025071728号-1  晋公网安备14060202000213号
晋公网安备14060202000213号