
Java基本数据类型
整数型,浮点型,布尔型,字符型 整数型: byte,short,int,long 浮点型: float,double 布尔型: boolean 字符型: char
基本类型和包装类型的区别
基本数据类型成员变量(未被static修饰) 存放在Java虚拟机的堆中
基本类型不一定被放在Java虚拟机的栈中,这取决于这个基本类型变量在哪个地方,如果它是作为方法中的局部变量,那么它是存放在栈中的,当这个基本类型变量被放在成员变量里面的时候,它才会被放到堆中。
当然被static修饰的基本类型一定是存放在Java虚拟机的堆中的。
包装类型的缓存机制
Java基本数据类型的包装类大部分都用到了缓存机制来提升性能 Byte,Short,Integer,Long这4种包装类默认创建了[-128,127]相应类型的缓存数据,Character创建了数值在[0,127]范围的缓存数据,Boolean直接返回TRUE或者FALSE
对于Integer,可以通过JVM参数 -XX:AutoBoxCacheMax 来设定范围,但是不能修改下限 实际使用的时候,不建议设置过大的值,防止浪费内存,或者OOM
equals方法和==的区别
== 对于基本类型是判断值是否相等,对于引用类型是判断地址是否相等 equals方法,因为所有类的顶层父类都是Object类,所以Object类中的equals方法判断的也是两个对象的内存地址是否相同 因此需要重写equals方法,实现对象和对象之间的内容比较,当然了,重写equals方法的时候也需要重写hashCode方法,来保证在集合中使用的正确性。
自动装箱和自动拆箱
什么是自动装箱? 自动装箱是Java在基本数据和包装类型之间的自动转换,在基本类型到包装类型转换时,会调用包装类型的valueOf方法
什么是自动拆箱?
package cn.meowrain;
public class Main{ public static void main(String[] args) { Integer i = Integer.valueOf(10); int j = i.intValue(); }}为什么浮点数运算的时候会有精度丢失的风险?
计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机时,只能被截断,所以就会导致小数精度发生损失的情况
如何解决浮点数运算的精度丢失问题?
BigDecimal 可以实现对浮点数的运算,不会造成精度丢失。通常情况下,大部分需要浮点数精确运算结果的业务场景(比如涉及到钱的场景)都是通过 BigDecimal 来做的。
BigDecimal的equals方法会比较精度还有值是否相等,BigDecimal的compareTo方法会比较值是否相等
Java高精度
BigDecimal, BigInteger
面向对象和面向过程的区别
面边过程编程和面向对象编程是两种常见的编程范式,两者的主要区别在于解决问题的方式不同:
面向过程编程: 面向过程会把解决问题的过程拆成一个一个方法,通过一个一个方法的执行去解决问题
面向对象编程: 会先抽象出对象,然后用对象执行方法的方式解决问题
面向对象编程开发的程序一般有下面的优点:
- 易维护: 由于良好的结构和封装性,面向对象程序通常更容易维护
- 易复用: 通过继承和多态,OOP设计使得代码更具有复用性,方便扩展功能
- 易扩展: 模块化设计使得系统扩展变得更加容易和灵活。
封装继承多态
封装是指将对象的属性和(数据)和方法(行为)捆绑在一起,并隐藏对象的内部实现细节,只暴露必要的接口给外部世界。有助于保护数据不被直接访问和修改,从而提高代码的安全性和可维护性。
继承是面向对象编程中的另外一个核心概念,允许一个类从另一个类中继承属性和方法,从而实现代码复用和层次结构,子类可以扩展或者修改父类的行为,不需要重新编写代码。
多态是指允许不同的对象对同一消息做出不同的响应,即同一方法可以根据发送对象的不同而采用多种不同的行为方式。多态的实现方式有:
- 方法重载: 同一个类中,方法名相同,参数列表不同,返回值类型可以相同也可以不同
- 方法重写: 子类中,方法名和参数列表与父类相同,返回值类型和异常类型也相同,但是方法体不同
- 接口实现: 一个类实现了一个接口,那么这个类就可以被视为是这个接口的一个实例,从而可以调用接口中的方法。
接口和抽象类的区别
接口偏向于定义行为规范,是对行为的抽象,强调“能不能做”,“具备什么能力” 抽象类偏向于定义共同的属性和方法,是对类的抽象,强调“是什么”的关系
共同点: 接口和多态都不能被实例化,只能被实现或者继承后才能创建具体的对象。
为什么要有hashCode
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashCode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashCode 值作比较,如果没有相符的 hashCode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashCode 值的对象,这时会调用 equals() 方法来检查 hashCode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
那为什么 JDK 还要同时提供这两个方法呢? 这是因为在一些容器(比如 HashMap、HashSet)中,有了 hashCode() 之后,判断元素是否在对应容器中的效率会更高(参考添加元素进HashSet的过程)!我们在前面也提到了添加元素进HashSet的过程,如果 HashSet 在对比的时候,同样的 hashCode 有多个对象,它会继续使用 equals() 来判断是否真的相同。也就是说 hashCode 帮助我们大大缩小了查找成本。
equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
String类的不可变性是如何被保证的?
-
String类被final修饰,也就是说String类是不可被继承的,不可被继承意味着没人能通过继承String类来修改String类的行为,从而保证了String类的不可变性。
-
底层的字符数组被final修饰
private final char value[];这意味着这个value的引用是不可变的,不能指向其他数组,但是数组中的字符是可以变的。 还需要进一步保护
-
没有对外暴露value的引用,可以看到前面用了private修饰,无法被外部类通过数组引用修改数组内容
-
String类也没有提供可以修改String内部数组的方法
String、StringBuffer、StringBuilder 的区别?
String是不可变的,StringBuilder和StringBuffer都继承自AbstractStringBuilder类,在AbstractStringBuilder中也是使用字符数组保存字符串,不过没有使用final和private关键字修饰
StringBuffer是线程安全的,里面大量使用了synchronized关键字来保证线程安全,而StringBuilder是线程不安全的。
String#equals() 和 Object#equals() 有何区别?
因为String是引用类型,String中的equals方法是被重写过的,比较的是String字符串的值是否相等,Object中的equals方法是没有被重写的,比较的是对象的内存地址是否相等。
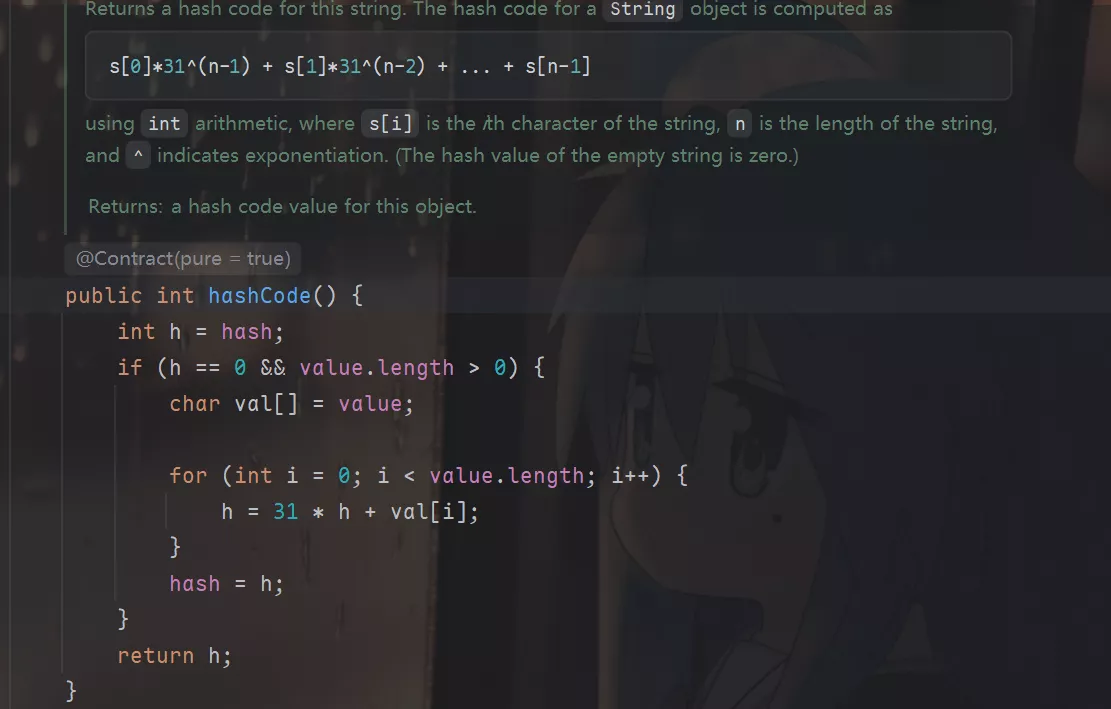
/** * Compares this string to the specified object. The result is {@code * true} if and only if the argument is not {@code null} and is a {@code * String} object that represents the same sequence of characters as this * object. * * @param anObject * The object to compare this {@code String} against * * @return {@code true} if the given object represents a {@code String} * equivalent to this string, {@code false} otherwise * * @see #compareTo(String) * @see #equalsIgnoreCase(String) */ public boolean equals(Object anObject) { if (this == anObject) { return true; } if (anObject instanceof String) { String anotherString = (String)anObject; int n = value.length; if (n == anotherString.value.length) { char v1[] = value; char v2[] = anotherString.value; int i = 0; while (n-- != 0) { if (v1[i] != v2[i]) return false; i++; } return true; } } return false; }String#intern 方法有什么作用?
String.intern() 是一个 native (本地) 方法,用来处理字符串常量池中的字符串对象引用。它的工作流程可以概括为以下两种情况: 常量池中已有相同内容的字符串对象:如果字符串常量池中已经有一个与调用 intern() 方法的字符串内容相同的 String 对象,intern() 方法会直接返回常量池中该对象的引用。
常量池中没有相同内容的字符串对象:如果字符串常量池中还没有一个与调用 intern() 方法的字符串内容相同的对象,intern() 方法会将当前字符串对象的引用添加到字符串常量池中,并返回该引用。
package org.example;
public class Tests {
public static void main(String[] args) { // 已经有一个字符串常量 "abc" String abc = "abc"; String str = new String("abc"); System.out.println(str.intern() == str); System.out.println(abc == str.intern()); }}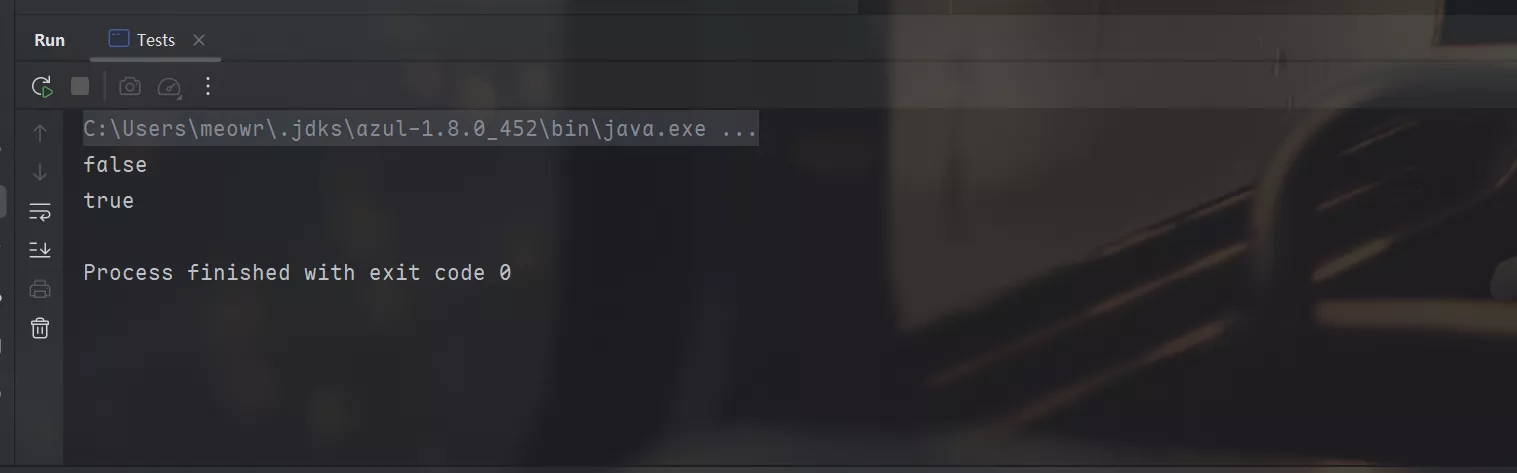
可以看到,str.intern() 返回的是字符串常量池中的引用,而不是字符串对象的引用,所以 str.intern() != str。 而 abc 是字符串常量池中的引用,所以 abc == str.intern()。
package org.example;
public class Tests {
public static void main(String[] args) { // 字符串常量池中之前没有"abc",所以 intern() 方法会将其添加到常量池中,并返回这个新创建的字符串对象的引用。 String str = new String("abc"); System.out.println(str.intern() == str);
}}这个例子中,str.intern() == str 为 false,因为 str.intern() 返回的是字符串常量池中的引用,而 str 是字符串对象的引用。
也就是说new String(“abc”)的时候,字面量”abc”在编译时就已经确定在常量池中了,运行时的new String()操作是基于已存在的字面量创建新对象,放在堆内存中。
异常
Exception 和 Error 有什么区别?
在Java中,所有的异常都有一个共同的祖先java.lang包中的Throwable类,Throwable类有两个重要的子类:
- Exception: 程序本身可以处理的异常,可以通过Catch进行捕获,Exception可以分为Checked Exception和Unchecked Exception。
- Error: 程序无法处理的异常,Error类的异常是由JVM抛出的 语法上虽然可以捕获,但是一般不建议捕获Error类的异常,因为Error类的异常是由JVM抛出的,程序中无法捕获,也无法处理。
Checked Exception 和 Unchecked Exception 有什么区别?
Checked Exception 即 受检查异常 ,Java 代码在编译过程中,如果受检查异常没有被 catch或者throws 关键字处理的话,就没办法通过编译。
Unchecked Exception 即 非受检查异常 ,Java 代码在编译过程中,如果非受检查异常没有被 catch或者throws 关键字处理的话,也可以通过编译,但是在运行时会抛出异常。
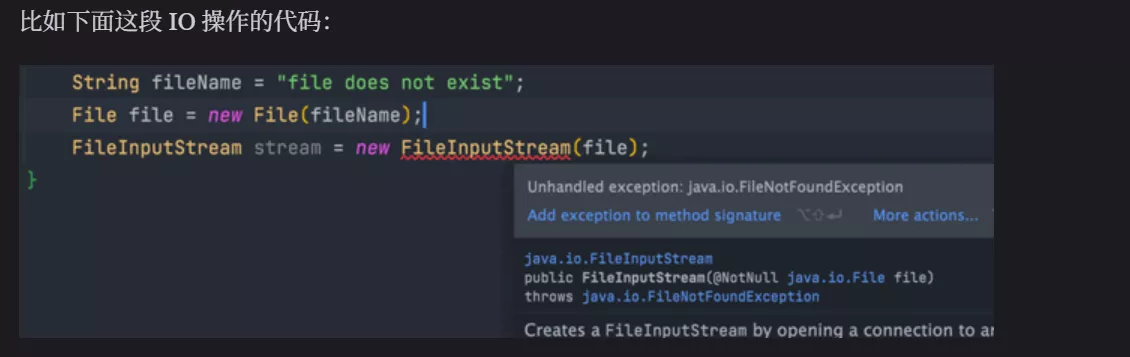
除了RuntimeException及其子类以外,其他的Exception类及其子类都属于受检查异常 。常见的受检查异常有:IO 相关的异常、ClassNotFoundException、SQLException…。
RuntimeException 及以下的异常类都被称为非受检查异常(Unchecked Exception),常见的非受检查异常有:ArrayIndexOutOfBoundsException、NullPointerException、ClassCastException…。
Throwable 类常用方法有哪些?
- String getMessage(): 返回异常发生时的详细信息
- String toString(): 返回异常发生时的简要描述
- String getLocalizedMessage(): 返回异常对象的本地化信息。使用 Throwable 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 getMessage()返回的结果相同
- void printStackTrace(): 在控制台上打印 Throwable 对象封装的异常信息
不要在 finally 语句块中使用 return! 当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。
什么是反射?
反射是一种在程序运行的时候,动态地获取类的信息并且操作类或者对象的能力。
发现错误或想要改进这篇文章?
在 GitHub 上编辑此页RSS / 网站地图
由 Astro 和 Fuwari 强力驱动
本网站代码 已开源 (22b02cb @ 2026-02-18 18:57:33)
 晋ICP备2025071728号-1
晋ICP备2025071728号-1  晋公网安备14060202000213号
晋公网安备14060202000213号