设计模式
[TOC]
面向对象相关知识
面向对象类关系 (继承、实现、依赖、关联、聚合、组合):https://www.cnblogs.com/zhongj/p/11169780.html
UML: https://blog.csdn.net/quyingzhe0217/article/details/133683814
创建型模式
创建型设计模式包括以下几种常见的模式:
工厂模式(Factory Pattern):通过工厂方法或抽象工厂来创建对象,将对象的创建过程封装起来,使得客户端代码与具体类解耦。
抽象工厂模式(Abstract Factory Pattern):提供一个接口,用于创建相关或依赖对象的家族,而不需要指定具体类。
单例模式(Singleton Pattern):确保一个类只有一个实例,并提供一个全局访问点来访问该实例。
建造者模式(Builder Pattern):将一个复杂对象的构建过程与其表示分离,使得同样的构建过程可以创建不同的表示。
原型模式(Prototype Pattern):通过复制现有对象来创建新对象,而不是通过实例化来创建。
结构型模式
结构型设计模式主要包括以下几种常见的模式: 适配器模式(Adapter Pattern):将一个类的接口转换成客户端所期望的另一个接口,使得原本不兼容的类可以一起工作。
桥接模式(Bridge Pattern):将抽象部分与实现部分分离,使它们可以独立地变化,从而提高系统的灵活性。
组合模式(Composite Pattern):将对象组合成树形结构,以表示 “部分 - 整体” 的层次结构,使得客户端可以统一地处理单个对象和组合对象。
装饰器模式(Decorator Pattern):动态地给对象添加额外的职责,同时又不改变其接口。
外观模式(Facade Pattern):提供一个统一的接口,用于访问子系统中的一组接口,从而简化客户端与子系统之间的交互。
享元模式(Flyweight Pattern):通过共享细粒度的对象,以减少内存使用和提高性能。
代理模式(Proxy Pattern):为其他对象提供一个代理,以控制对这个对象的访问。
行为模式
行为型设计模式主要包括以下几种常见的模式:
观察者模式(Observer Pattern):定义了一种一对多的依赖关系,使得多个观察者对象可以同时监听并收到被观察者对象的通知。
策略模式(Strategy Pattern):定义了一系列算法,并将每个算法封装起来,使它们可以相互替换,从而使算法的变化独立于使用算法的客户端。
命令模式(Command Pattern):将请求封装成对象,以使得可以用不同的请求对客户端进行参数化,同时支持请求的排队、记录和撤销。
迭代器模式(Iterator Pattern):提供一种顺序访问聚合对象中各个元素的方法,而又不暴露该对象的内部表示。
状态模式(State Pattern):允许对象在内部状态发生改变时改变其行为,使对象看起来像是修改了其类。
责任链模式(Chain of Responsibility Pattern):将请求的发送者和接收者解耦,使多个对象都有机会处理请求,从而避免请求的发送者与接收者之间的耦合关系。
访问者模式(Visitor Pattern):在不改变被访问类的前提下,定义了一种新的访问操作,使得可以在不修改被访问类的情况下对其进行操作。
中介者模式(Mediator Pattern):定义了一个中介对象,封装了一组对象之间的交互方式,使其能够独立地改变交互方式。
备忘录模式(Memento Pattern):在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,从而可以在以后恢复到这个状态。
解释器模式(Interpreter Pattern):给定一个语言,定义它的文法的一种表示,并定义一个解释器,用于解释语言中的句子。
工厂方法模式 factory_method
工厂方法模式是一种创建型设计模式, 其在父类中提供一个创建对象的方法, 允许子类决定实例化对象的类型。
问题: 假设你正在开发一款物流管理应用。 最初版本只能处理卡车运输, 因此大部分代码都在位于名为 卡车的类中。
一段时间后, 这款应用变得极受欢迎。 你每天都能收到十几次来自海运公司的请求, 希望应用能够支持海上物流功能。
这可是个好消息。 但是代码问题该如何处理呢? 目前, 大部分代码都与 卡车类相关。 在程序中添加 轮船类需要修改全部代码。 更糟糕的是, 如果你以后需要在程序中支持另外一种运输方式, 很可能需要再次对这些代码进行大幅修改。
最后, 你将不得不编写繁复的代码, 根据不同的运输对象类, 在应用中进行不同的处理。
解决方案:

乍看之下, 这种更改可能毫无意义: 我们只是改变了程序中调用构造函数的位置而已。 但是, 仔细想一下, 现在你可以在子类中重写工厂方法, 从而改变其创建产品的类型。
但有一点需要注意:仅当这些产品具有共同的基类或者接口时, 子类才能返回不同类型的产品, 同时基类中的工厂方法还应将其返回类型声明为这一共有接口。

举例来说, 卡车 Truck 和 轮船 Ship 类都必须实现 运输 Transport 接口, 该接口声明了一个名为 deliver 交付的方法。 每个类都将以不同的方式实现该方法: 卡车走陆路交付货物, 轮船走海路交付货物。 陆路运输 RoadLogistics 类中的工厂方法返回卡车对象, 而 海路运输 SeaLogistics 类则返回轮船对象。
调用工厂方法的代码 (通常被称为客户端代码) 无需了解不同子类返回实际对象之间的差别。 客户端将所有产品视为抽象的 运输 。 客户端知道所有运输对象都提供 交付方法, 但是并不关心其具体实现方式。
以上的实现已经写在 factory_method 文件夹里面了
Logistics 相当于下面的 Creator,RoadLogistic 和 SeaLogistic 相当于 ConcreteCreatorA 和 ConcreteCreatorB
Transport 相当于 Product 接口,下面的 Ship 和 Truck 是实现这个接口的实体类

工厂方法应用场景:
当你在编写代码的过程中, 如果无法预知对象确切类别及其依赖关系时, 可使用工厂方法。
工厂方法将创建产品的代码与实际使用产品的代码分离, 从而能在不影响其他代码的情况下扩展产品创建部分代码。
例如, 如果需要向应用中添加一种新产品, 你只需要开发新的创建者子类, 然后重写其工厂方法即可。
就像上面我们写的运输货物的例子一样,假如现在多出个飞机运输,我们只需要创建一个 AirPlane类,然后让它 implements
Transport接口,实现其中的 transport函数就可以了
同时需要创建一个 FlightLogistic,继承 Logistics抽象类,然后重写就可以
如果你希望用户能扩展你软件库或框架的内部组件, 可使用工厂方法。
继承可能是扩展软件库或框架默认行为的最简单方法。 但是当你使用子类替代标准组件时, 框架如何辨识出该子类?
解决方案是将各框架中构造组件的代码集中到单个工厂方法中, 并在继承该组件之外允许任何人对该方法进行重写。
让我们看看具体是如何实现的。 假设你使用开源 UI 框架编写自己的应用。 你希望在应用中使用圆形按钮, 但是原框架仅支持矩形按钮。 你可以使用 圆形按钮 RoundButton 子类来继承标准的 按钮 Button 类。 但是, 你需要告诉 UI 框架 UIFramework 类使用新的子类按钮代替默认按钮。 为了实现这个功能, 你可以根据基础框架类开发子类 圆形按钮 UIUIWithRoundButtons , 并且重写其 createButton 创建按钮方法。 基类中的该方法返回 按钮对象, 而你开发的子类返回 圆形按钮对象。 现在, 你就可以使用 圆形按钮 UI 类代替 UI 框架类。 就是这么简单!
如果你希望复用现有对象来节省系统资源, 而不是每次都重新创建对象, 可使用工厂方法。 在处理大型资源密集型对象 (比如数据库连接、 文件系统和网络资源) 时, 你会经常碰到这种资源需求。
让我们思考复用现有对象的方法:
首先, 你需要创建存储空间来存放所有已经创建的对象。
当他人请求一个对象时, 程序将在对象池中搜索可用对象。
… 然后将其返回给客户端代码。
如果没有可用对象, 程序则创建一个新对象 (并将其添加到对象池中)。
这些代码可不少! 而且它们必须位于同一处, 这样才能确保重复代码不会污染程序。
可能最显而易见, 也是最方便的方式, 就是将这些代码放置在我们试图重用的对象类的构造函数中。 但是从定义上来讲, 构造函数始终返回的是新对象, 其无法返回现有实例。
因此, 你需要有一个既能够创建新对象, 又可以重用现有对象的普通方法。 这听上去和工厂方法非常相像。

优缺点

生成器模式
https://refactoringguru.cn/design-patterns/builder
生成器模式是一种创建型设计模式, 使你能够分步骤创建复杂对象。 该模式允许你使用相同的创建代码生成不同类型和形式的对象。
问题
假设有这样一个复杂对象, 在对其进行构造时需要对诸多成员变量和嵌套对象进行繁复的初始化工作。
这些初始化代码通常深藏于一个包含众多参数且让人基本看不懂的构造函数中; 甚至还有更糟糕的情况, 那就是这些代码散落在客户端代码的多个位置。
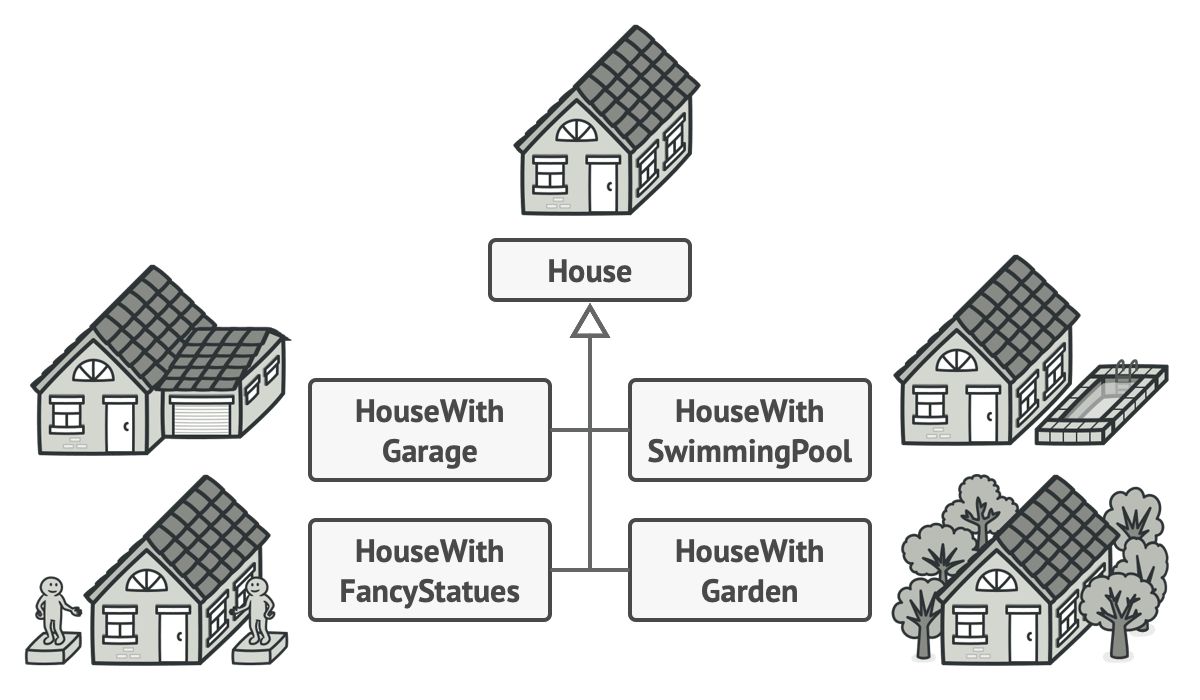 如果为每种可能的对象都创建一个子类, 这可能会导致程序变得过于复杂。
例如, 我们来思考如何创建一个 房屋 House 对象。 建造一栋简单的房屋, 首先你需要建造四面墙和地板, 安装房门和一套窗户,
然后再建造一个屋顶。 但是如果你想要一栋更宽敞更明亮的房屋, 还要有院子和其他设施 (例如暖气、 排水和供电设备), 那又该怎么办呢?
如果为每种可能的对象都创建一个子类, 这可能会导致程序变得过于复杂。
例如, 我们来思考如何创建一个 房屋 House 对象。 建造一栋简单的房屋, 首先你需要建造四面墙和地板, 安装房门和一套窗户,
然后再建造一个屋顶。 但是如果你想要一栋更宽敞更明亮的房屋, 还要有院子和其他设施 (例如暖气、 排水和供电设备), 那又该怎么办呢?
最简单的方法是扩展 房屋基类, 然后创建一系列涵盖所有参数组合的子类。 但最终你将面对相当数量的子类。 任何新增的参数 (例如门廊类型) 都会让这个层次结构更加复杂。
另一种方法则无需生成子类。 你可以在 房屋基类中创建一个包括所有可能参数的超级构造函数, 并用它来控制房屋对象。 这种方法确实可以避免生成子类, 但它却会造成另外一个问题。
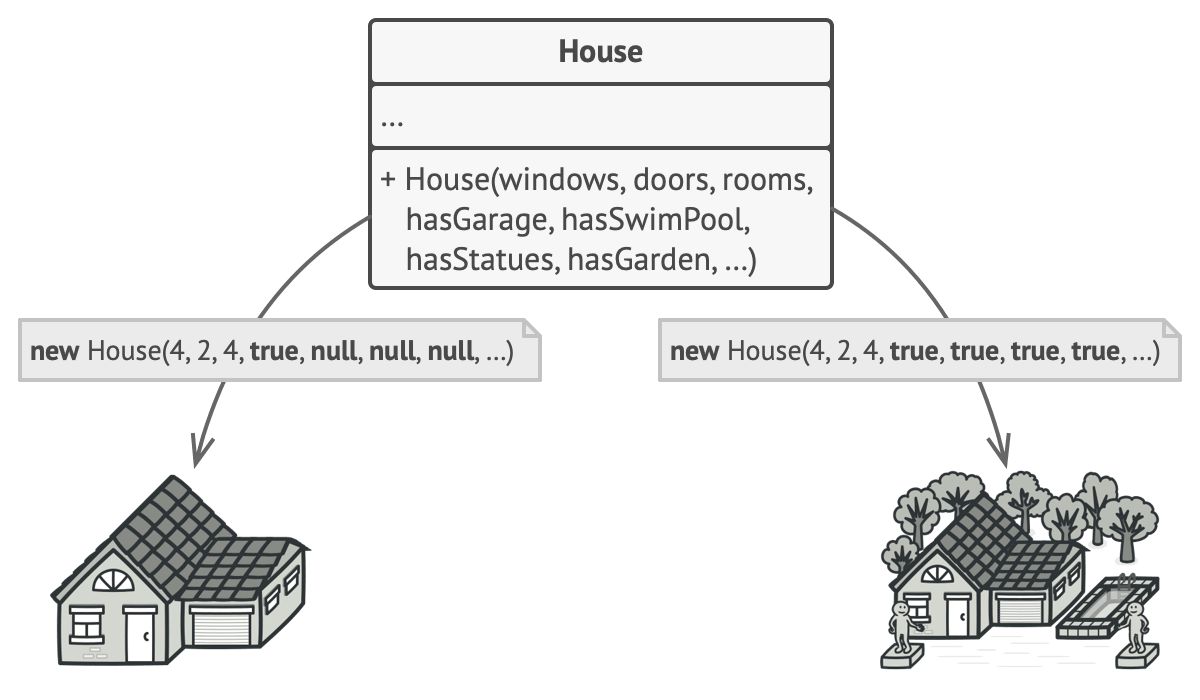
拥有大量输入参数的构造函数也有缺陷: 这些参数也不是每次都要全部用上的。
通常情况下, 绝大部分的参数都没有使用, 这使得对于构造函数的调用十分不简洁。 例如, 只有很少的房子有游泳池, 因此与游泳池相关的参数十之八九是毫无用处的。
解决方案: 生成器模式建议将对象构造代码从产品类中抽取出来, 并将其放在一个名为生成器的独立对象中。
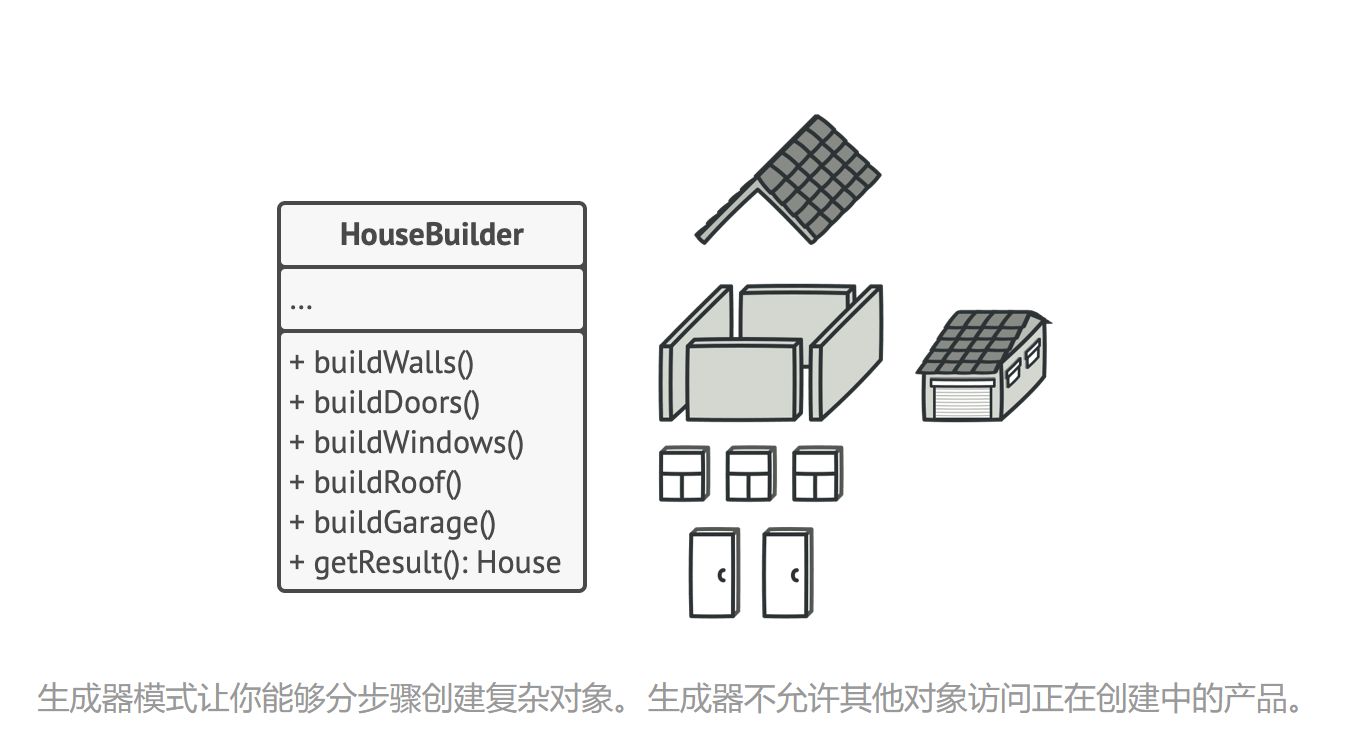
该模式会将对象构造过程划分为一组步骤, 比如 buildWalls 创建墙壁和 buildDoor 创建房门创建房门等。 每次创建对象时, 你都需要通过生成器对象执行一系列步骤。 重点在于你无需调用所有步骤, 而只需调用创建特定对象配置所需的那些步骤即可。
当你需要创建不同形式的产品时, 其中的一些构造步骤可能需要不同的实现。 例如, 木屋的房门可能需要使用木头制造, 而城堡的房门则必须使用石头制造。
在这种情况下, 你可以创建多个不同的生成器, 用不同方式实现一组相同的创建步骤。 然后你就可以在创建过程中使用这些生成器 (例如按顺序调用多个构造步骤) 来生成不同类型的对象。
例如, 假设第一个建造者使用木头和玻璃制造房屋, 第二个建造者使用石头和钢铁, 而第三个建造者使用黄金和钻石。 在调用同一组步骤后, 第一个建造者会给你一栋普通房屋, 第二个会给你一座小城堡, 而第三个则会给你一座宫殿。 但是, 只有在调用构造步骤的客户端代码可以通过通用接口与建造者进行交互时, 这样的调用才能返回需要的房屋。
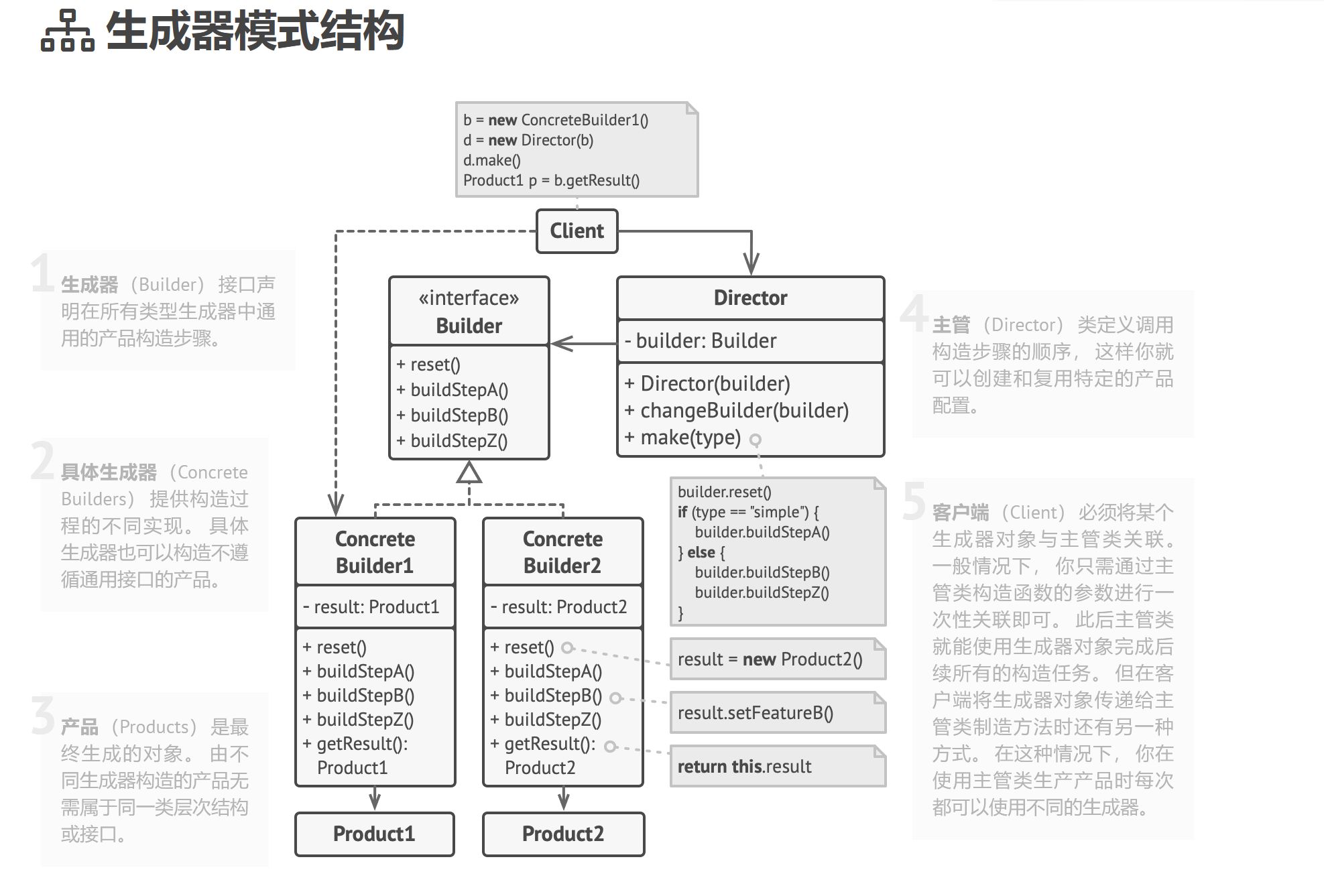
主管
你可以进一步将用于创建产品的一系列生成器步骤调用抽取成为单独的主管类。 主管类可定义创建步骤的执行顺序, 而生成器则提供这些步骤的实现。
严格来说, 你的程序中并不一定需要主管类。 客户端代码可直接以特定顺序调用创建步骤。 不过, 主管类中非常适合放入各种例行构造流程, 以便在程序中反复使用。
此外, 对于客户端代码来说, 主管类完全隐藏了产品构造细节。 客户端只需要将一个生成器与主管类关联, 然后使用主管类来构造产品, 就能从生成器处获得构造结果了。
结构
使用
在文件夹 builder_patter
中,我创建了 House 实体类,对应结构中的 Client,HouseBuilder 接口对应其中的 Builder, 产品为 Roof,Wall,Door,Window,分别在 ConcretHouseBuilder 中进行建造,ConcretHouseBuilder 实现了 HouseBuilder 接口。
HouseBuilderEngineer 对应图中的主管,负责定义构造步骤的顺序。

下面我们来看一下生成器模式的应用场景
1. 使用生成器模式可避免 “重叠构造函数 (telescoping constructor)” 的出现。 假设你的构造函数中有十个可选参数, 那么调用该函数会非常不方便; 因此, 你需要重载这个构造函数, 新建几个只有较少参数的简化版。 但这些构造函数仍需调用主构造函数, 传递一些默认数值来替代省略掉的参数。 生成器模式让你可以分步骤生成对象, 而且允许你仅使用必须的步骤。 应用该模式后, 你再也不需要将几十个参数塞进构造函数里了。
2. 当你希望使用代码创建不同形式的产品 (例如石头或木头房屋) 时, 可使用生成器模式 如果你需要创建的各种形式的产品, 它们的制造过程相似且仅有细节上的差异, 此时可使用生成器模式。
基本生成器接口中定义了所有可能的制造步骤, 具体生成器将实现这些步骤来制造特定形式的产品。 同时, 主管类将负责管理制造步骤的顺序。
3. 使用生成器构造组合树或其他复杂对象。 生成器模式让你能分步骤构造产品。 你可以延迟执行某些步骤而不会影响最终产品。 你甚至可以递归调用这些步骤, 这在创建对象树时非常方便。 生成器在执行制造步骤时, 不能对外发布未完成的产品。 这可以避免客户端代码获取到不完整结果对象的情况。
优缺点

抽象工厂模式
单例模式
https://refactoringguru.cn/design-patterns/singleton
单例模式还有七种写法,见 https://juejin.cn/post/6844904105891250189
我写的代码是懒汉式的
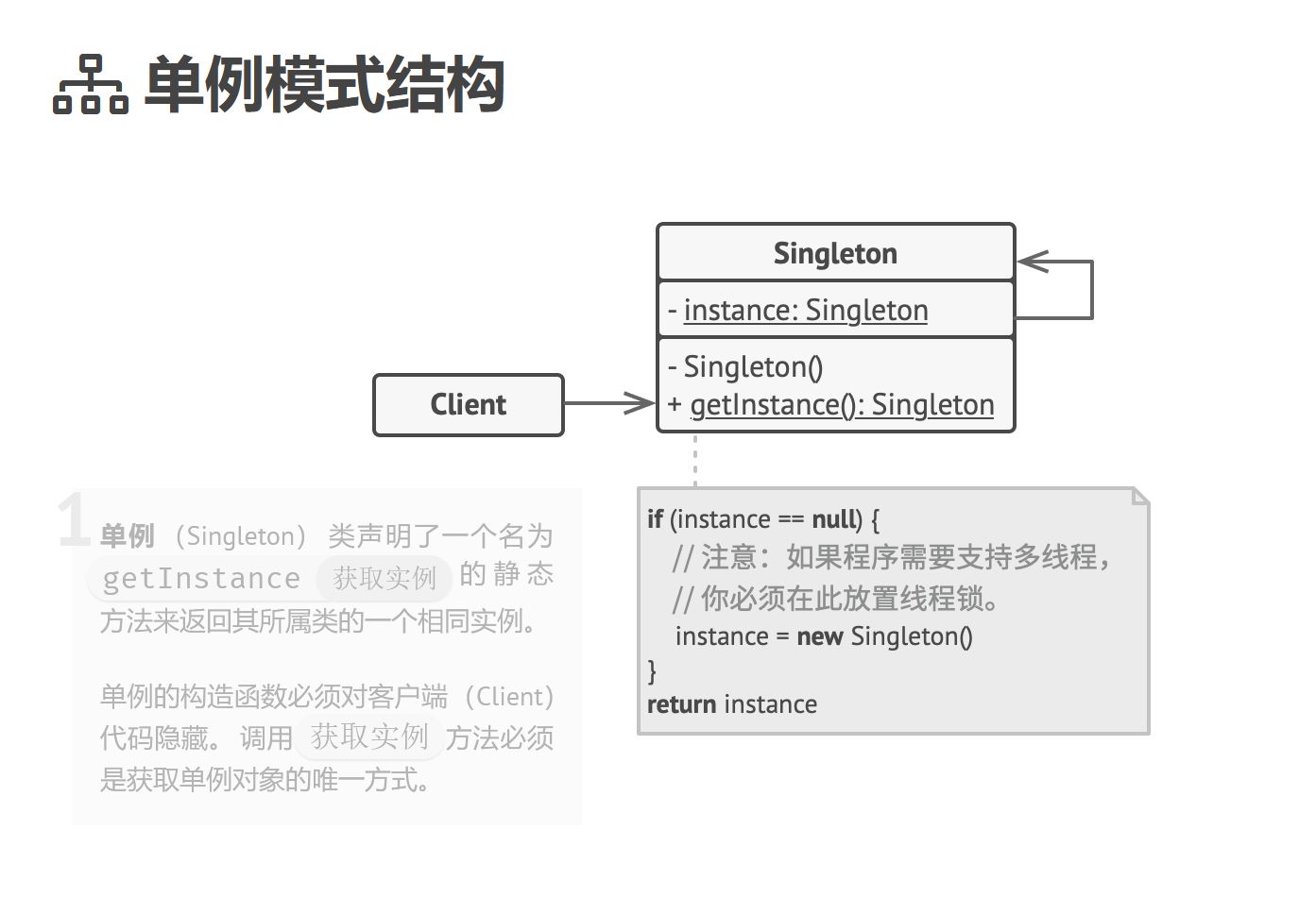
单例模式是一种创建型设计模式, 让你能够保证一个类只有一个实例, 并提供一个访问该实例的全局节点。 单例模式同时解决了两个问题, 所以违反了单一职责原则:
1. 保证一个类只有一个实例。 为什么会有人想要控制一个类所拥有的实例数量? 最常见的原因是控制某些共享资源 (例如数据库或文件) 的访问权限。
它的运作方式是这样的: 如果你创建了一个对象, 同时过一会儿后你决定再创建一个新对象, 此时你会获得之前已创建的对象, 而不是一个新对象。
注意, 普通构造函数无法实现上述行为, 因为构造函数的设计决定了它必须总是返回一个新对象。
2. 为该实例提供一个全局访问节点。 还记得你 (好吧, 其实是我自己) 用过的那些存储重要对象的全局变量吗? 它们在使用上十分方便, 但同时也非常不安全, 因为任何代码都有可能覆盖掉那些变量的内容, 从而引发程序崩溃。
和全局变量一样, 单例模式也允许在程序的任何地方访问特定对象。 但是它可以保护该实例不被其他代码覆盖。
还有一点: 你不会希望解决同一个问题的代码分散在程序各处的。 因此更好的方式是将其放在同一个类中, 特别是当其他代码已经依赖这个类时更应该如此。
使用
所有单例的实现都包含以下两个相同的步骤:
- 将默认构造函数设为私有, 防止其他对象使用单例类的 new 运算符。
- 新建一个静态构建方法作为构造函数。 该函数会 “偷偷” 调用私有构造函数来创建对象, 并将其保存在一个静态成员变量中。 此后所有对于该函数的调用都将返回这一缓存对象。
如果你的代码能够访问单例类, 那它就能调用单例类的静态方法。 无论何时调用该方法, 它总是会返回相同的对象。
结构
代码在 singleton_pattern 文件夹下
应用场景

优缺点

原型模式
https://refactoringguru.cn/design-patterns/prototype
原型模式是一种创建型设计模式, 使你能够复制已有对象, 而又无需使代码依赖它们所属的类。
问题
如果你有一个对象, 并希望生成与其完全相同的一个复制品, 你该如何实现呢? 首先, 你必须新建一个属于相同类的对象。 然后, 你必须遍历原始对象的所有成员变量, 并将成员变量值复制到新对象中。
不错! 但有个小问题。 并非所有对象都能通过这种方式进行复制, 因为有些对象可能拥有私有成员变量, 它们在对象本身以外是不可见的。 直接复制还有另外一个问题。 因为你必须知道对象所属的类才能创建复制品, 所以代码必须依赖该类。 即使你可以接受额外的依赖性, 那还有另外一个问题: 有时你只知道对象所实现的接口, 而不知道其所属的具体类, 比如可向方法的某个参数传入实现了某个接口的任何对象。
解决方案
原型模式将克隆过程委派给被克隆的实际对象。模式为所有支持克隆的对象声明了一个通用接口, 该接口让你能够克隆对象, 同时又无需将代码和对象所属类耦合。 通常情况下, 这样的接口中仅包含一个 克隆方法。
所有的类对克隆方法的实现都非常相似。 该方法会创建一个当前类的对象, 然后将原始对象所有的成员变量值复制到新建的类中。 你甚至可以复制私有成员变量, 因为绝大部分编程语言都允许对象访问其同类对象的私有成员变量。
支持克隆的对象即为原型。 当你的对象有几十个成员变量和几百种类型时, 对其进行克隆甚至可以代替子类的构造。
其运作方式如下: 创建一系列不同类型的对象并不同的方式对其进行配置。 如果所需对象与预先配置的对象相同, 那么你只需克隆原型即可, 无需新建一个对象。