本文最后更新于 2024-06-18,文中内容可能已过时。
参考文档
https://jacktang816.github.io/post/tinyhttpdread/
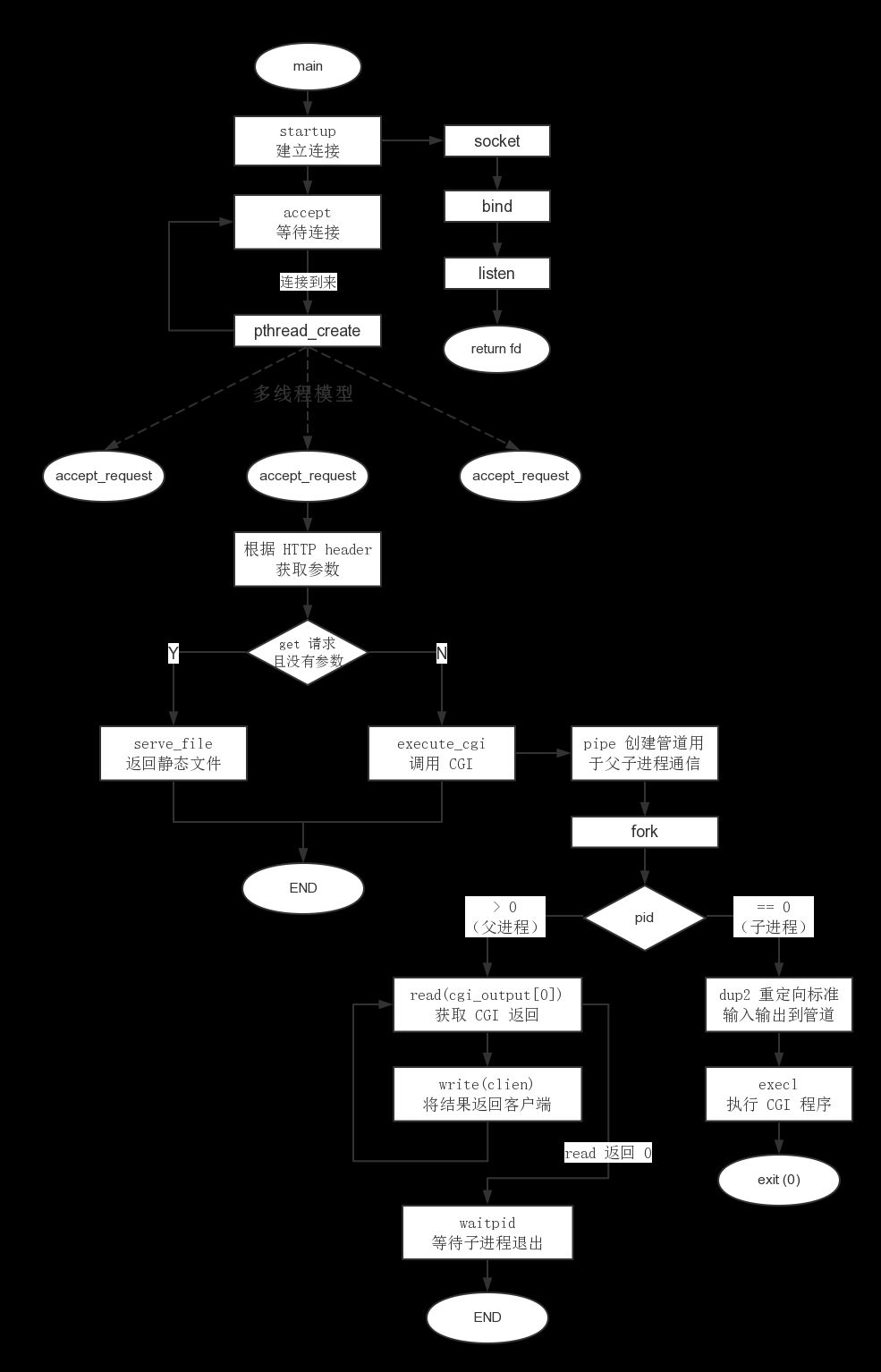
执行过程
HTTP
HTTP请求头
当然,下面是一个带有 \r\n 行结尾的 HTTP 请求头示例:
1
2
3
4
5
6
7
8
9
GET /index.html HTTP/1.1\r\n
Host: www.example.com\r\n
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8\r\n
Accept-Language: en-US,en;q=0.5\r\n
Accept-Encoding: gzip, deflate\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
\r\n
解释
每一行都是一个 HTTP 头字段,使用 \r\n(回车符和换行符)来表示行结束。
最后一行的 \r\n 表示头部结束,之后的内容(如果有)是请求的主体。
分解示例
请求行 :
1
GET /index.html HTTP/1.1\r\n
GET 是 HTTP 方法。/index.html 是请求的路径。HTTP/1.1 是 HTTP 版本。
头字段 :
1
2
3
4
5
6
7
Host: www.example.com\r\n
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8\r\n
Accept-Language: en-US,en;q=0.5\r\n
Accept-Encoding: gzip, deflate\r\n
Connection: keep-alive\r\n
Upgrade-Insecure-Requests: 1\r\n
Host: 指定请求的主机名(必须字段)。User-Agent: 指定发出请求的客户端软件信息。Accept: 指定客户端可接受的响应内容类型。Accept-Language: 指定客户端可接受的响应语言。Accept-Encoding: 指定客户端可接受的响应内容编码(如压缩)。Connection: 指定是否保持连接。Upgrade-Insecure-Requests: 指定客户端是否要求安全的连接升级。
空行 :
空行表示 HTTP 请求头的结束,接下来如果有数据就是请求的主体。
HTTP响应头
当然,下面是一个包含 \r\n 作为行结束符的 HTTP 响应头示例:
1
2
3
4
5
6
7
8
HTTP/1.1 200 OK\r\n
Date: Tue, 18 Jun 2024 12:28:53 GMT\r\n
Server: jdbhttpd/0.1.0\r\n
Last-Modified: Tue, 18 Jun 2024 12:28:53 GMT\r\n
Content-Type: text/html\r\n
Content-Length: 1234\r\n
Connection: keep-alive\r\n
\r\n
解释
每一行都是一个 HTTP 头字段,使用 \r\n(回车符和换行符)来表示行结束。
最后一行的 \r\n 表示头部结束,之后的内容(如果有)是响应的主体。
分解示例
状态行 :
HTTP/1.1:HTTP 版本。200 OK:状态码和状态描述,表示请求成功。
头字段 :
1
2
3
4
5
6
Date: Tue, 18 Jun 2024 12:28:53 GMT\r\n
Server: jdbhttpd/0.1.0\r\n
Last-Modified: Tue, 18 Jun 2024 12:28:53 GMT\r\n
Content-Type: text/html\r\n
Content-Length: 1234\r\n
Connection: keep-alive\r\n
Date:响应的日期和时间。Server:服务器软件的信息。Last-Modified:响应内容的最后修改时间。Content-Type:响应内容的类型(这里是 HTML)。Content-Length:响应内容的长度(以字节为单位)。Connection:控制连接的管理方式(这里是保持连接)。
空行 :
空行表示 HTTP 响应头的结束,接下来是响应的主体(如果有)。
accept_request() 函数
好的,根据注释描述这个函数的执行过程如下:
accept_request 函数
这个函数的主要任务是处理 HTTP 请求,根据请求的内容返回相应的网页或执行 CGI 程序。它分为几个主要步骤:读取请求头、解析请求方法和 URL、处理 GET/POST 请求、判断文件类型和权限、返回文件内容或执行 CGI 脚本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
void accept_request ( void * arg )
{
// socket
int client = ( intptr_t ) arg ; //client套接字
char buf [ 1024 ]; //存储从套接字中读取到的内容
int numchars ; //表示读取到的字节数
char method [ 255 ]; //存储请求方法
char url [ 255 ]; //存储url
char path [ 512 ]; //存储路径
size_t i , j ; //两个索引指针
struct stat st ; //存储网页文件的文件信息
int cgi = 0 ; //cgi是否启用,如果设置为1,默认启用
char * query_string = NULL ; //请求参数
// 根据上面的Get请求,可以看到这边就是取第一行
// 这边都是在处理第一条http信息
numchars = get_line ( client , buf , sizeof ( buf )); //先从套接字读取一行数据到buf中,然后返回读取到的字节数
i = 0 ;
j = 0 ;
// 第一行字符串提取Get
//"GET / HTTP/1.1\n"
while ( ! ISspace ( buf [ j ]) && ( i < sizeof ( method ) - 1 ))
{
//读到GET后的space后,循环就终止了,正好把GET读取到method数组中了
method [ i ] = buf [ j ];
i ++ ;
j ++ ;
}
// 结束
method [ i ] = '\0' ;
// 如果两个都不是,直接返回是不支持的请求类型
//strcasecmd 和 strcmp一样,相等返回0
if ( strcasecmp ( method , "GET" ) && strcasecmp ( method , "POST" ))
{
unimplemented ( client );
return ;
}
// 如果是POST,cgi置为1
if ( strcasecmp ( method , "POST" ) == 0 )
cgi = 1 ;
i = 0 ; // i指针归零
// 跳过空格
while ( ISspace ( buf [ j ]) && ( j < sizeof ( buf )))
j ++ ;
// 得到 "/" 注意:如果你的http的网址为http://192.168.0.23:47310/index.html
// 那么你得到的第一条http信息为GET /index.html HTTP/1.1,那么
// 解析得到的就是/index.html
while ( ! ISspace ( buf [ j ]) && ( i < sizeof ( url ) - 1 ) && ( j < sizeof ( buf )))
{
url [ i ] = buf [ j ];
i ++ ;
j ++ ;
}
url [ i ] = '\0' ;
// 判断Get请求
if ( strcasecmp ( method , "GET" ) == 0 )
{
query_string = url ;
while (( * query_string != '?' ) && ( * query_string != '\0' ))
query_string ++ ;
if ( * query_string == '?' )
{
cgi = 1 ;
* query_string = '\0' ;
query_string ++ ;
}
}
// 路径
sprintf ( path , "htdocs%s" , url );
// 默认地址,解析到的路径如果为/,则自动加上index.html
if ( path [ strlen ( path ) - 1 ] == '/' )
strcat ( path , "index.html" );
// 获得文件信息
if ( stat ( path , & st ) == - 1 )
{
// 把所有http信息读出然后丢弃
while (( numchars > 0 ) && strcmp ( " \n " , buf )) /* read & discard headers */
numchars = get_line ( client , buf , sizeof ( buf ));
// 没有找到
not_found ( client );
}
else
{
mode_t file_type = st . st_mode & S_IFMT ;
if ( file_type == S_IFDIR )
strcat ( path , "/index.html" );
// 如果你的文件默认是有执行权限的,自动解析成cgi程序,如果有执行权限但是不能执行,会接受到报错信号
if (( st . st_mode & S_IXUSR ) ||
( st . st_mode & S_IXGRP ) ||
( st . st_mode & S_IXOTH ))
cgi = 1 ;
if ( ! cgi )
// 接读取文件返回给请求的http客户端
serve_file ( client , path );
else
// 执行cgi文件
execute_cgi ( client , path , method , query_string );
}
// 执行完毕关闭socket
close ( client );
}
执行过程描述
初始化和读取请求 :
将传入的 arg 转换为客户端的套接字 client。
初始化缓冲区 buf 用于存储读取的数据,初始化其他变量。
调用 get_line 从客户端套接字读取一行数据到 buf,并将读取到的字节数存储在 numchars 中。
解析请求方法 :
从 buf 中提取请求方法(如 GET 或 POST),并存储在 method 数组中。
如果请求方法既不是 GET 也不是 POST,则返回未实现的错误。
处理 POST 请求 :
如果请求方法是 POST,则将 cgi 标志置为 1。
提取 URL :
跳过空格,继续从 buf 中提取 URL,并存储在 url 数组中。
处理 GET 请求的查询字符串 :
如果请求方法是 GET,则进一步解析 URL 中的查询字符串(如果有)。
构建文件路径 :
根据提取的 URL 构建文件路径,存储在 path 数组中。
如果 URL 以 / 结尾,自动添加 index.html。
获取文件信息 :
调用 stat 函数获取文件信息并存储在 st 结构中。
如果文件不存在(即 stat 返回 -1),则读取并丢弃所有的 HTTP 请求头信息,并返回 404 错误。
处理文件信息 :
检查文件类型是否为目录,如果是,则自动添加 index.html。
检查文件是否具有执行权限,如果有,则将 cgi 标志置为 1。
处理文件或执行 CGI :
如果未启用 CGI,则读取文件内容并返回给客户端。
如果启用了 CGI,则执行相应的 CGI 脚本。
关闭套接字 :
通过这些步骤,accept_request 函数能够处理基本的 HTTP 请求,包括静态文件的返回和 CGI 脚本的执行。
badrequest() 函数 notfound()函数 unimplemented()函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
void bad_request ( int client )
{
char buf [ 1024 ];
sprintf ( buf , "HTTP/1.0 400 BAD REQUEST \r\n " );
send ( client , buf , sizeof ( buf ), 0 );
sprintf ( buf , "Content-type: text/html \r\n " );
send ( client , buf , sizeof ( buf ), 0 );
sprintf ( buf , " \r\n " );
send ( client , buf , sizeof ( buf ), 0 );
sprintf ( buf , "<P>Your browser sent a bad request, " );
send ( client , buf , sizeof ( buf ), 0 );
sprintf ( buf , "such as a POST without a Content-Length. \r\n " );
send ( client , buf , sizeof ( buf ), 0 );
}
这个就简单了,直接往buf里面写入字符串,包括响应头,响应类型和内容,然后发给客户端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// 如果资源没有找到得返回给客户端下面的信息
void not_found ( int client )
{
char buf [ 1024 ];
sprintf ( buf , "HTTP/1.0 404 NOT FOUND \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , SERVER_STRING );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "Content-Type: text/html \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , " \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "<HTML><TITLE>Not Found</TITLE> \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "<BODY><P>The server could not fulfill \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "your request because the resource specified \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "is unavailable or nonexistent. \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "</BODY></HTML> \r\n " );
send ( client , buf , strlen ( buf ), 0 );
}
这个也是,把NOTFOUND的内容发过去
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
// 如果方法没有实现,就返回此信息
void unimplemented ( int client )
{
char buf [ 1024 ];
sprintf ( buf , "HTTP/1.0 501 Method Not Implemented \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , SERVER_STRING );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "Content-Type: text/html \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , " \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "<HTML><HEAD><TITLE>Method Not Implemented \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "</TITLE></HEAD> \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "<BODY><P>HTTP request method not supported. \r\n " );
send ( client , buf , strlen ( buf ), 0 );
sprintf ( buf , "</BODY></HTML> \r\n " );
send ( client , buf , strlen ( buf ), 0 );
}
如果方法没有实现,就返回此信息
cat()函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
void cat ( int client , FILE * resource )
{
char buf [ 1024 ]; // 定义一个缓冲区,大小为 1024 字节
// 从文件中读取一行内容到缓冲区 buf 中
fgets ( buf , sizeof ( buf ), resource );
// 循环读取文件内容,直到文件结束
while ( ! feof ( resource ))
{
// 将缓冲区 buf 中的内容发送给客户端
send ( client , buf , strlen ( buf ), 0 );
// 再次从文件中读取一行内容到缓冲区 buf 中
fgets ( buf , sizeof ( buf ), resource );
}
}
这个代码的作用是,从FILE*中读取内容到buf缓冲区中,每次读取1024字节,读进来就发送给客户端,然后循环往复,直到读完这个文件为止
servefile()函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// 如果不是CGI文件,直接读取文件返回给请求的http客户端
void serve_file ( int client , const char * filename )
{
FILE * resource = NULL ;
int numchars = 1 ;
char buf [ 1024 ];
// 默认字符
buf [ 0 ] = 'A' ;
buf [ 1 ] = '\0' ;
while (( numchars > 0 ) && strcmp ( " \n " , buf )) /* read & discard headers */
numchars = get_line ( client , buf , sizeof ( buf ));
resource = fopen ( filename , "r" );
if ( resource == NULL )
not_found ( client );
else
{
headers ( client , filename );
cat ( client , resource );
}
fclose ( resource );
}
serve_file() 函数的主要作用是处理 HTTP 请求并返回一个文件的内容给客户端。如果请求的文件存在且不是 CGI 脚本,则会将文件内容发送给客户端。下面是对这个函数的详细解释:
主要步骤和详细解释:
初始化变量 :
1
2
3
FILE * resource = NULL ;
int numchars = 1 ;
char buf [ 1024 ];
resource:用于存储打开的文件指针。numchars:用于记录读取的字符数,初始化为1。buf:缓冲区,用于存储从客户端读取的数据。
默认字符设置 :
1
2
buf [ 0 ] = 'A' ;
buf [ 1 ] = '\0' ;
这段代码将 buf 的第一个字符设置为 'A',并将第二个字符设置为终止符 '\0',以确保缓冲区不为空。
读取并丢弃请求头部 :
1
2
while (( numchars > 0 ) && strcmp ( " \n " , buf )) /* read & discard headers */
numchars = get_line ( client , buf , sizeof ( buf ));
通过循环调用 get_line() 函数,从客户端读取一行数据并存储在 buf 中。
该循环持续读取,直到读取到一个空行(即仅包含 '\n' 的行),表示 HTTP 请求头部结束。
读取的每一行都被丢弃,因为 serve_file() 只关心请求的文件内容。
尝试打开文件 :
1
2
3
resource = fopen ( filename , "r" );
if ( resource == NULL )
not_found ( client );
尝试以只读模式打开请求的文件。
如果文件不存在或无法打开,则调用 not_found() 函数向客户端返回 404 错误。
发送文件内容 :
1
2
3
4
5
else
{
headers ( client , filename );
cat ( client , resource );
}
如果文件成功打开,则首先调用 headers() 函数发送 HTTP 响应头部。
然后调用 cat() 函数,将文件内容逐行读取并发送给客户端。
关闭文件 :
相关函数解释:
get_line() :
从客户端读取一行数据,直到遇到换行符 '\n',并将其存储在缓冲区 buf 中。
not_found() :
向客户端发送 404 错误,表示请求的文件未找到。
headers() :
发送 HTTP 响应头部,告知客户端响应的文件类型和状态。
cat() :
将文件内容逐行读取,并通过 send() 函数发送给客户端。
这个函数的设计确保了在处理非 CGI 请求时,能够正确读取并返回文件内容给客户端,同时处理可能的错误情况,如文件未找到等。喵~
getline()函数
源码部分
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
int get_line ( int sock , char * buf , int size )
{
int i = 0 ; // 缓冲区的索引
char c = '\0' ; // 从套接字读取的字符
int n ; // recv() 函数读取的字符数
// 循环读取字符,直到缓冲区满或遇到换行符
while (( i < size - 1 ) && ( c != '\n' ))
{
// 从套接字读取一个字符
n = recv ( sock , & c , 1 , 0 );
if ( n > 0 )
{
// 如果字符是回车符('\r'),需要检查下一个字符
if ( c == '\r' )
{
// 偷窥下一个字符,但不从输入队列中移除它
n = recv ( sock , & c , 1 , MSG_PEEK );
// 如果下一个字符是换行符('\n'),从套接字读取它
if (( n > 0 ) && ( c == '\n' ))
recv ( sock , & c , 1 , 0 );
else
// 如果下一个字符不是换行符,将回车符视为换行符
c = '\n' ;
}
// 将字符存储在缓冲区中
buf [ i ] = c ;
i ++ ;
}
else
// 如果没有读取到字符,视为换行符以结束行
c = '\n' ;
}
// 空字符终止缓冲区,使其成为有效的 C 字符串
buf [ i ] = '\0' ;
// 返回存储在缓冲区中的字符数,不包括空字符
return ( i );
}
代码作用和流程
这段代码的主要作用是从套接字中循环读取字符,处理 HTTP 请求头部信息。它具体的流程如下:
循环读取字符 :
从套接字中读取一个字符到变量 c 中。
如果成功读取到字符,继续处理。
处理回车符号 '\r' :
如果读取到的字符是回车符号 '\r',接下来检查它的下一个字符。
使用 MSG_PEEK 标志从套接字中偷窥下一个字符(但不将其移出输入队列)。
如果下一个字符是换行符 '\n',则从套接字中真正读取该字符,使 c 变为 '\n'。
如果下一个字符不是换行符,直接将 c 设置为 '\n'。
存储字符 :
将处理后的字符 c 存储到缓冲区 buf 中。
更新缓冲区索引 i,指向下一个存储位置。
处理读取失败或结束情况 :
如果没有成功读取到字符(可能是连接关闭或出错),将 c 设置为换行符 '\n',结束行读取。
结束读取并终止缓冲区 :
循环结束后,在缓冲区末尾添加一个空字符 '\0',以形成有效的 C 字符串。
返回存储在缓冲区中的字符数,不包括空字符。
清晰的表述
这段代码的作用是循环读取字符,具体流程如下:
先从套接字读取一个字符到 c 中。
如果成功读取到字符:
检查该字符是否为回车符 '\r':
如果是回车符 '\r',继续检查下一个字符:
使用 MSG_PEEK 标志偷窥下一个字符:
如果下一个字符是换行符 '\n',则从套接字中读取该字符到 c 中,此时 c 为 '\n'。
如果下一个字符不是换行符,则将 c 设置为 '\n'。
如果不是回车符 '\r',则将读取到的字符存储到缓冲区 buf 中。
如果没有成功读取到字符(可能是连接关闭或出错),将 c 设置为换行符 '\n',结束行读取。
每次读取到字符后,将其存储到缓冲区 buf 中,并更新缓冲区索引 i。
循环结束后,在缓冲区末尾添加一个空字符 '\0',表示字符串结束。
最终,函数返回存储在缓冲区 buf 中的字符数,不包括结尾的空字符 '\0'。