
1037 字
5 分钟
MySQL中如何解决深度分页问题
MySQL中如何解决深度分页问题

问题描述
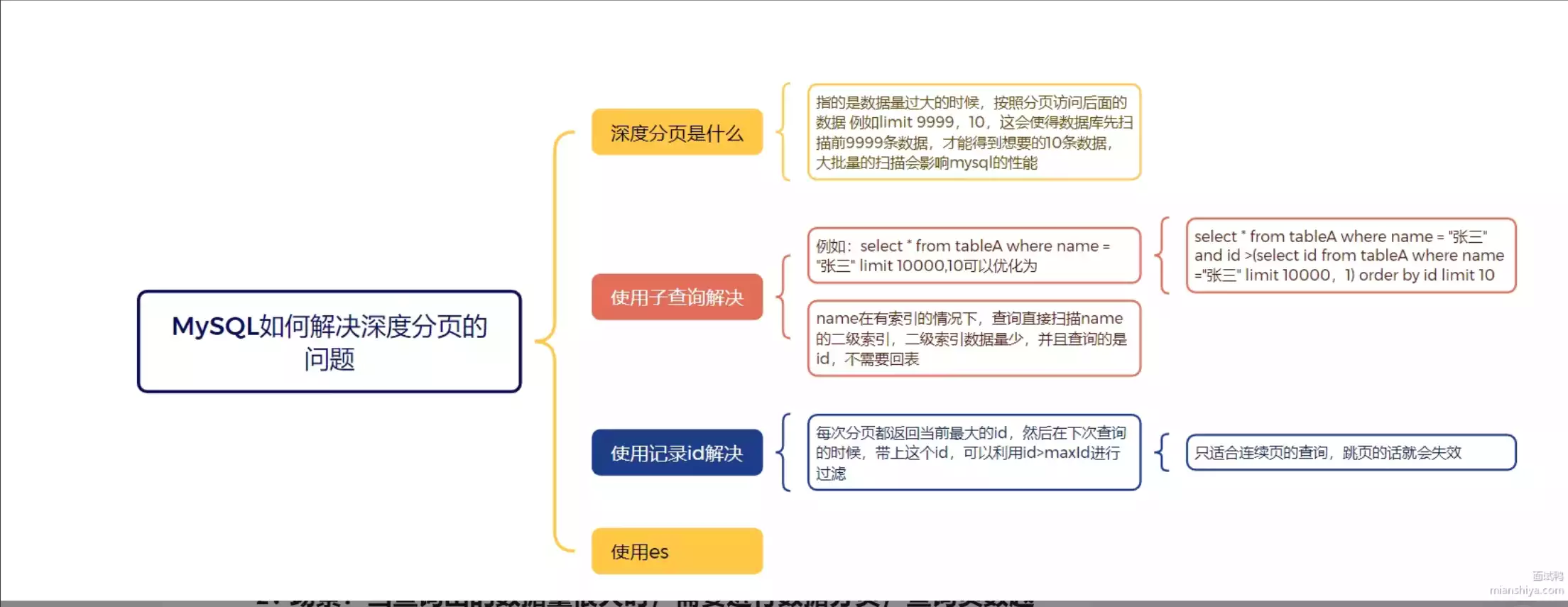
深度分页,指的是当数据量很大的时候,按照分页访问后面的数据,例如 limit 9999990,10 这会使得数据库要扫描前面的9999990条数据,才能得到最终的10条数据,大批量的扫描数据会增加数据库的负载,影响性能。
三种优化方式
记录id
每次分页都返回当前的最大id,然后下次查询的时候,带上这个id,就能利用id > maxid过滤了。 这种查询适合 连续查询的情况,如果跳页的话就不生效了。
普通分页的痛点:
SELECT * FROM article ORDER BY id LIMIT 10 OFFSET 100000;MySQL 需要先扫描并跳过 前 100000 行,然后再返回后 10 行。(这里说下底层原因)
OFFSET 越大,性能越差。
我们每次查询时带上 上一次返回的最大 id,下一页就只要取 id > last_id 的记录。
不依赖 OFFSET,直接利用索引顺序扫描。
select * from products limit 0,10; -- 第一页select * from products where id > 10 limit 10; -- 第二页select * from products where id > 20 limit 10; -- 第三页select * from products where id > 30 limit 10; -- 第四页子查询
这里其实和记录id的优化方式是一样的,只不过这里用的是子查询。理论上我们应该先去查询到上一页的最大id,然后再查询下一页的数据。
SELECT * from products where id > (SELECT id from products order by created_at desc limit 199999,1) order by created_at desc limit 10;这里我们给表的created_at建索引,可以利用created_at的二级索引进行扫描,然后利用id > 上一次查询的最大id进行过滤,最后再利用created_at的二级索引进行排序,最后再利用limit进行分页。

子查询只读索引列(最好覆盖:筛选列 + 排序列 + id),IO 最小化。 外层 JOIN 回表范围仅为一页大小(如 20 条),成本可控。
相较于原来的
SELECT * FROM products order by created_at desc limit 200000,10;这个虽然可以利用created_at的二级索引进行扫描,但是它需要对每条记录进行一次回表操作,还要丢弃掉前200000条记录,性能较差。

join方法
SELECT p.* FROM products p INNER JOIN ( SELECT id FROM products ORDER BY created_at DESC limit 10 OFFSET 200000 ) AS page_results on p.id = page_results.id order by p.created_at desc;这个和上面的子查询方式是一样的,只不过这里用的是join。
使用es
直接上elasticsearch,利用它本身分页的特性,进行优化。
use pages;-- 创建商品表CREATE TABLE `products` ( `id` BIGINT AUTO_INCREMENT COMMENT '自增主键ID', `product_name` VARCHAR(255) NOT NULL COMMENT '商品名称', `category_id` INT NOT NULL COMMENT '分类ID', `price` DECIMAL(10, 2) NOT NULL COMMENT '价格', `created_at` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='商品表';
-- 在排序字段上创建索引,这是至关重要的CREATE INDEX `idx_created_at` ON `products` (`created_at`);
-- (可选)创建一个更实用的联合索引,例如按分类查找再按时间排序CREATE INDEX `idx_category_created` ON `products` (`category_id`, `created_at`);
-- 修改MySQL的语句结束符,以便在存储过程中使用分号DELIMITER $$
-- 创建一个名为 insert_mock_products 的存储过程CREATE PROCEDURE `insert_mock_products`(IN insert_count INT)BEGIN -- 定义一个循环计数器 DECLARE i INT DEFAULT 1;
-- 开始循环 WHILE i <= insert_count DO INSERT INTO `products` ( `product_name`, `category_id`, `price`, `created_at` ) VALUES ( -- 生成一个像 'Product 123' 这样的随机商品名 CONCAT('Product ', i), -- 生成一个 1 到 50 之间的随机分类ID FLOOR(1 + RAND() * 50), -- 生成一个 10.00 到 1000.99 之间的随机价格 ROUND(10 + RAND() * 990.99, 2), -- 生成一个从现在开始,逐步往前推移的时间,确保时间戳的唯一和顺序性 -- 这里用秒作为递减单位,可以确保排序的稳定性 DATE_SUB(NOW(), INTERVAL i SECOND) ); -- 计数器加1 SET i = i + 1; END WHILE;END$$
-- 将语句结束符恢复为默认的分号DELIMITER ;
-- 调用存储过程,并传入你想要插入的数据量CALL insert_mock_products(1000000);发现错误或想要改进这篇文章?
在 GitHub 上编辑此页 MySQL中如何解决深度分页问题
© 2021 - 2026 MeowRain 采用
CC BY-NC-SA 4.0 许可
RSS / 网站地图
由 Astro 和 Fuwari 强力驱动
本网站代码 已开源 (22b02cb @ 2026-02-18 18:57:28)
 晋ICP备2025071728号-1
晋ICP备2025071728号-1
 晋公网安备14060202000213号
晋公网安备14060202000213号
RSS / 网站地图
由 Astro 和 Fuwari 强力驱动
本网站代码 已开源 (22b02cb @ 2026-02-18 18:57:28)
晋ICP备2025071728号-1
晋公网安备14060202000213号